
Eine Datenplattform mit einem großen Datenbestand wirkt auf den ersten Blick oft leistungsfähiger und umfassender als eine Plattform mit bewusst schlankerem, aber möglicherweise präziser ausgewähltem Speicherumfang. Im Datenzeitalter ist es zwar naheliegend, möglichst viele Daten zu sammeln und langfristig vorzuhalten, doch mit wachsendem Datenvolumen steigen auch die Herausforderungen und Risiken erheblich. Das gilt nicht nur für On-Premises-Umgebungen, sondern ebenso für Datenplattformen in der Cloud, in denen sich große Datenmengen schnell in höheren Folgeaufwänden niederschlagen können. Denn je mehr Daten gespeichert werden, desto komplexer werden Verwaltung, Verarbeitung, Absicherung und Kontrolle der Datenbestände. Deshalb ist nicht nur die Menge der gespeicherten Daten entscheidend, sondern vor allem die Frage, ob sie wirklich einen geschäftlichen Mehrwert liefern und sinnvoll gesteuert werden.
Daher sollten Firmen das Wachstum und die Zusammensetzung des Speicherplatzes auf ihren Datenplattformen genau verstehen. In diesem Artikel erklären wir, wie man erfolgreich ein Storage-Monitoring aufbaut und geeignete Maßnahmen und Erkenntnisse ableitet. Folgende Punkte sollten bedacht werden, wenn ein Unternehmen noch zögert, ein Speicherplatz-Monitoring einzuführen:
Speicherplatz kostet nicht nur On-Prem viel, sondern führt auch in der Cloud zu Folgekosten
In der Cloud wirkt Speicherplatz auf den ersten Blick günstig oder sogar nebensächlich, weil die reinen Speicherkosten im Vergleich zu früher deutlich niedriger erscheinen. In der Praxis entstehen jedoch durch wachsende Datenmengen oft Folgekosten, die erst später sichtbar werden, etwa bei Compute, Egress, Backups oder Replikation zur Ausfallsicherheit. Mit Egress-Gebühren werden Kosten bezeichnet, die von Cloud-Anbietern (wie AWS, Azure, Google Cloud) für das Herunterladen oder Übertragen von Daten aus oder in deren Netzwerk oder anderen Regionen erhoben werden. Gerade Compute-Kosten können stark steigen, wenn große Datenmengen verarbeitet werden müssen, auch wenn sich dieser Effekt mit guter Partitionierung, sinnvoller Clusterung, effizienten Dateiformaten und passenden Query-Mustern teilweise vermeiden lässt. Das Risiko zusätzlicher Kosten steigt grundsätzlich mit der Datenmenge – insbesondere dann, wenn Daten ohne aktive Entscheidung angesammelt werden und niemand mehr weiß, ob sie noch gebraucht werden.
Security - durch geringe Speicherkosten wird auch immer mehr gespeichert
Durch die niedrigen Speicherkosten in der Cloud wird häufig deutlich mehr Datenmaterial gespeichert, als wirklich nötig wäre. Das erhöht im Falle eines Security Incidents den potenziellen Schaden, weil mehr personenbezogene Daten, vertrauliche Informationen oder Geschäftsgeheimnisse betroffen sein können. Gleichzeitig wird auch die Einhaltung von Löschfristen und anderen Compliance-Vorgaben deutlich aufwendiger, wenn große Datenbestände über lange Zeiträume vorgehalten werden. Wenn Systeme aus Backups wiederhergestellt werden, müssen nach einem Ausfall oder bei einer Datenmigrationen auf eine andere Plattform, z. B. im Rahmen einer EXIT-Strategie, verlängern sich Recovery-Zeiten direkt mit dem Datenvolumen - und damit auch die Zeit, in der geschäftskritische Prozesse stillstehen. Mehr Datenvolumen führt daher zu einem erhöhten Vendor-Lockin durch erhöhte Recovery-Zeiten.
Speicherverbrauch ist nicht nur ein Kostenproblem, sondern ein Steuerungsproblem
Speicherverbrauch sollte nicht nur als technische oder finanzielle Kennzahl betrachtet werden, sondern vor allem als Frage der aktiven Steuerung. Entscheidend ist, welche Datenbestände für das Geschäft wirklich relevant sind und welche nur historisch gewachsen sind, ohne noch einen klaren Nutzen zu haben. Hinzu kommt die Frage, welche Daten Folgekosten in Verarbeitung, Governance, Security und Compliance sowie erhöhten Governance-Aufwand verursachen – Faktoren, die typischerweise nur auf Managementebene priorisiert und budgetiert werden können. Damit wird Speicherverbrauch zu einer Management-Frage: Wächst die Datenmenge kontrolliert und nachvollziehbar, oder entwickelt sie sich ungebremst und ohne klare Verantwortlichkeiten? Genau an dieser Stelle braucht es Transparenz und Regeln, um Datenbestände bewusst zu entwickeln, statt nur passiv anwachsen zu lassen.
Speicher-Monitoring macht das Problem transparent – gelöst wird es aber über Governance!
Speicher-Monitoring ist nicht nur der erste Schritt, sondern auch das dauerhafte Kontrollinstrument, um sichtbar zu machen, wo Datenbestände wachsen und welche Bereiche besonders auffällig sind. Die eigentliche Lösung liegt jedoch nicht im Messen allein, sondern in Governance-Strukturen, die festlegen, wer Daten dauerhaft speichern darf und nach welchen Regeln dies geschieht. Dazu gehören klare Verantwortlichkeiten wie Data Owner, definierte Entscheidungen zu Vorhaltedauern, Archivierung und Löschung sowie nachvollziehbare Kriterien für unterschiedliche Datentypen wie produktive Daten, Analyse-Daten, Sandbox-Daten oder temporäre Daten. Ohne Governance bleibt Monitoring nur Transparenz ohne Durchgriff, also ein bloßes Erkennen des Problems ohne Handlungsfähigkeit. Gleichzeitig kann genau diese Transparenz helfen, den Bedarf nach besseren Richtlinien und Verantwortlichkeiten überhaupt erst deutlich zu machen.
Speicherwachstum als Frühindikator für Architekturprobleme
Ein starkes Wachstum des Speicherverbrauchs ist oft kein Zufall, sondern ein Hinweis auf grundlegende Probleme in der Architektur oder in den Datenprozessen. Häufige Ursachen sind etwa ETL-Pipelines, die komplette Tabellen statt nur Deltas laden, oder Historisierungsprozesse ohne echtes Löschkonzept. Auch dauerhaft vorliegende Staging-Tabellen, mehrfach kopierte Daten in Fachbereichssilos oder unbefristet gespeicherte Rohdaten aus AI-/ML-Projekten treiben den Speicherbedarf unnötig in die Höhe. Hinzu kommt schlechte Datenmodellierung, die Redundanz erzeugt und damit Speicher sowie Verarbeitung belastet. Speicherwachstum ist deshalb oft ein früher Indikator dafür, dass technische Entscheidungen, Datenflüsse oder Betriebsmodelle nicht vollständig durchdacht sind und deshalb nicht skalieren.
Grundsätzlich kann ein Monitoring selbst gebaut oder über eine kommerzielle Lösung eingekauft werden. Der Build-Ansatz bietet dabei mehrere überzeugende Vorteile: Die Einstiegskosten sind gering, weil die benötigten Metadaten - etwa Systemkataloge, information_schema oder Storage-Meta-APIs - in jeder Datenbank bereits vorhanden sind. Mit SQL lässt sich der aktuelle Stand, etwa Top-Consumer oder die größten Tabellen, sofort und ohne zusätzliche Infrastruktur abfragen. Wachstumstrends werden sichtbar, sobald die Metadaten regelmäßig historisiert werden. Hinzu kommt, dass sensible Metainformationen das Unternehmen nicht verlassen und kein externer Vendor Zugriff auf die Plattform benötigt - ein wichtiger Punkt für Unternehmen mit strengen Datenschutz- oder On-Prem-Anforderungen. Schließlich bleibt die Lösung vollständig anpassbar: Eigene Metriken, Alerts und Visualisierungen können exakt auf interne Bedürfnisse wie Kostenstellen, Retentionsregeln oder fachliche Gruppierungen zugeschnitten werden, ohne an einen Anbieter gebunden zu sein.
Der wesentliche Nachteil des Build-Ansatzes liegt darin, dass ein grundlegendes technisches Verständnis für Datenbankstrukturen und den Aufbau eines Monitorings vorhanden sein muss. Wer dieses Know-how im Team hat, profitiert jedoch von einer schlanken, flexiblen Lösung, die sich mit überschaubarem Aufwand betreiben lässt. Aus diesem Grund konzentriert sich dieser Artikel auf den Build-Ansatz.
Aufsetzen eines eigenen Monitorings
Der Ausgangspunkt für ein eigenes Storage-Monitoring sind die Meta-Tabellen der Datenplattform, in denen der belegte Speicherplatz je Tabelle aufgelistet wird. Meist zeigen diese Tabellen nur den aktuellen Stand der Größe an. Historisiert man diese Tabellen - z. B. täglich, wöchentlich oder monatlich - so lässt sich das Wachstum der Tabellen berechnen und bestimmen, welche Tabellen in der Datenbank aktuell stark wachsen. Aus der Praxis empfiehlt es sich, täglich einen Snapshot der Metatabelle in eine eigene Historientabelle zu schreiben – also eine Zeile je Tabelle mit dem aktuellen Speicherverbrauch und einem Datumswert. Auf dieser Historientabelle lässt sich dann eine View aufbauen, die das Wachstum automatisch berechnet, etwa als Differenz zum Vortag, zur Vorwoche oder zum Vormonat. So entsteht mit minimalem Aufwand eine belastbare Zeitreihe, die direkt als Grundlage für Dashboards und Alerting dienen kann.
Aktuell große Tabellen sind das Problem von heute und stark wachsende Tabellen eventuell das Problem von morgen.
Je nach Datenbanksystem unterscheidet sich dabei, ob die Größe als komprimierter On-Disk-Verbrauch oder als logische, unkomprimierte Datenmenge angegeben wird - ein wichtiger Hinweis beim Vergleich zwischen verschiedenen Systemen. Die folgende Tabelle gibt eine Übersicht einiger gängiger Datenbanken sowie der zugehörigen Metatabellen:
| Datenbank | Metatabelle | Beschreibung | Link |
|---|---|---|---|
|
Amazon Redshift
|
SVV_TABLE_INFO | Systemview für Storage-/Table-Analyse. In der Spalte SIZE steht der Speicherplatzverbrauch. | SVV_TABLE_INFO - Amazon Redshift |
DB2

|
SYSCAT.TABLES, ADMINTABINFO |
Der Systemkatalog (SYSCAT) liefert Informationen zu Tabellen. In der View ADMINTABINFO stehen die genauen Werte in den Spalten DATA_OBJECT_L_SIZE bzw. DATA_OBJECT_P_SIZE sowie der Speicherplatzbedarf für die zugehörigen Indizes in den Spalten INDEX_OBJECT_L_SIZE und INDEX_OBJECT_P_SIZE. | ADMINTABINFO and ADMIN_GET_TAB_INFO |
EXASOL

|
EXA_ALL_OBJECT_SIZES, EXA_DBA_OBJECT_SIZES |
Liefert Objektgrößen für Tabellen und weitere Datenbankobjekte. In der Spalte RAW_OBJECT_SIZE wird das unkomprimierte Volumen der Daten angegeben und in der Spalte MEM_OBJECT_SIZE das komprimierte. | EXA_DBA_OBJECT_SIZES - System Table | Exasol Documentation |
MariaDB

|
information_schema.TABLES | Analog zu MySQL, da MariaDB ein Fork von MySQL ist. | Information Schema TABLES Table | Server | MariaDB Documentation |
MySQL

|
information_schema.TABLES | Im Schema INFORMATION_SCHEMA zeigt die Tabelle „TABLES“ Daten zu allen Tabellen. In der Spalte DATA_LENGTH steht der Datenverbrauch der Daten in Byte, in der Spalte INDEX_LENGTH der Datenverbrauch des zugehörigen Indexes. Summiert man die beiden Werte, erhält man den Datenverbrauch der Tabelle. | MySQL 9.7 Reference Manual :: INFORMATION_SCHEMA TABLES Table |
Oracle

|
DBA_SEGMENTS, ALL_SEGMENTS, USER_SEGMENTS |
Die Tabelle DBA_SEGMENTS enthält Segmentgrößen je Objekt. Filtert man auf „WHERE SEGMENT_TYPE = 'TABLE'“ erhält man nur Tabellen. Im SEGMENT_NAME steht dann der Tabellenname. In der Spalte Bytes steht die Größe der Tabelle. | Database Reference |
PostgreSQL

|
|
In PostgreSQL stehen die Informationen nicht in einer klassischen Metatabelle, sondern können über Funktionen abgefragt werden. | 53.32. pg_tables |
|
Snowflake
|
INFORMATION_SCHEMA. TABLE_STORAGE_METRICS |
In dieser View ist die Information zum Speicherplatz enthalten. Um die Tabelle anzusehen, braucht der:die Nutzer:in die Rolle ACCOUNTADMIN. Danach findet sich die Information in der Spalte ACTIVE_BYTES. Außerdem existieren die Spalten TIME_TRAVEL_BYTES und FAILSAFE_BYTES, die den Datenverbrauch der Tabellen für die Timetravel- und Failsafe-Funktion bereitstellen. | TABLE_STORAGE_METRICS view | Snowflake Documentation |
Exkurs zum Unterschied zwischen Gigabyte und Gibibyte: Die Angabe des Speicherplatzes in Datenbanken erfolgt meist in Byte. Um mit Bytes zu rechnen, gibt es zwei Rechensysteme. In dem Gigabyte-System wird mit dem Dezimalsystem (Umrechnungsfaktor 1000) gerechnet, im Gibibyte-System (Umrechnungsfaktor 1024) mit dem Binärsystem. Im Kontext von Speicherplatz ist das Gibibyte-System das richtige. Im Sprachgebrauch wird aber immer Gigabyte gesagt - auch wenn eigentlich Gibibyte gemeint sind. Daher ist der Umrechnungsfaktor immer 1024 und nicht 1000.
Aufbau eines Monitorings
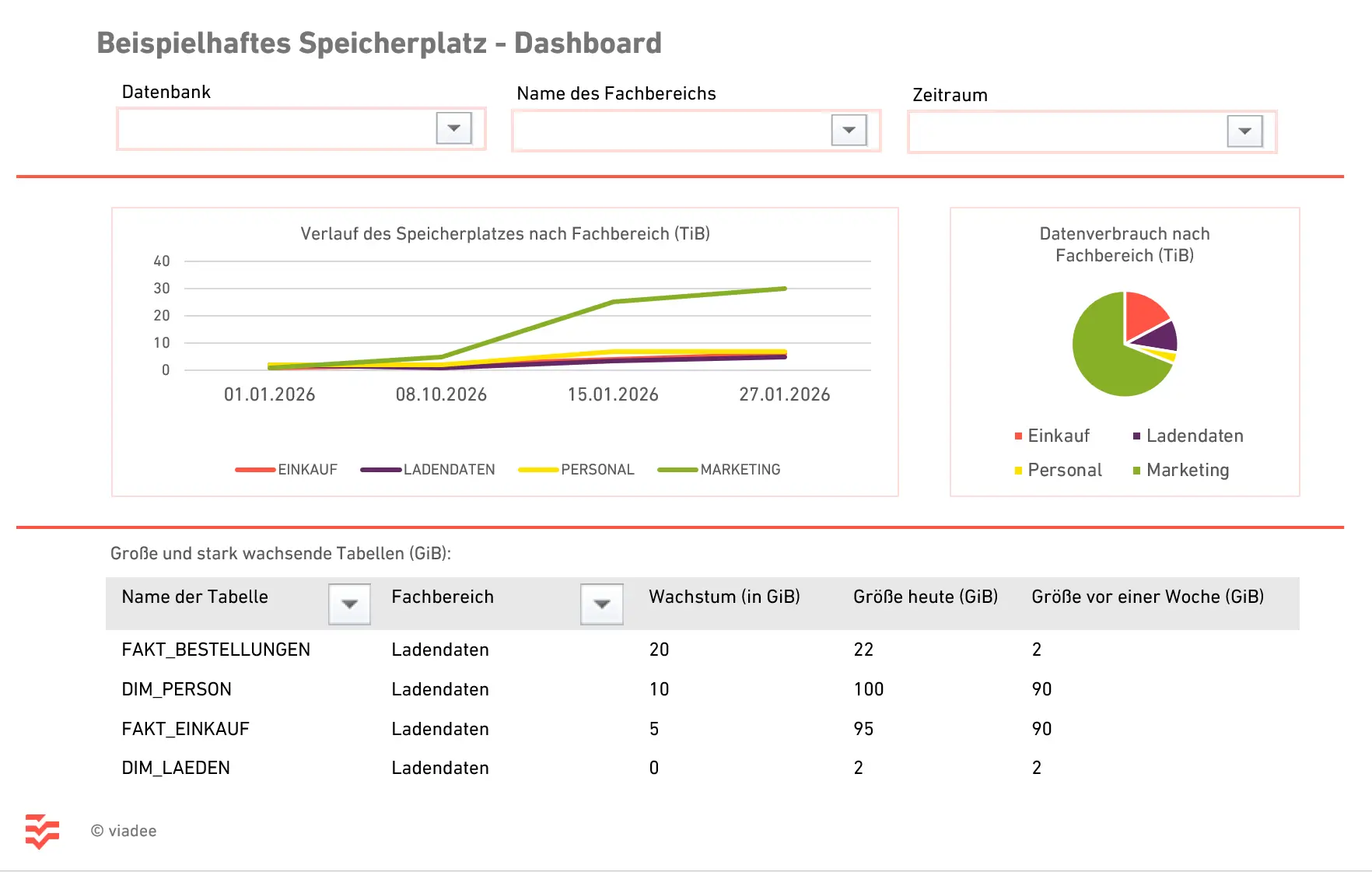
Sobald die Metadaten historisiert sind, lässt sich das Tabellenwachstum und die Entwicklung über die Zeit in einem Dashboard visualisieren. Hier kann man z. B. Power BI oder Grafana als dedizierte Dashboard-Tools nutzen oder Ad-hoc-Visualisierung in Jupyter Notebooks anzeigen lassen.
Im Dashboard ist es wichtig, geeignete Filter bereitzustellen und für jede Information die passende Visualisierungsform zu wählen. Als Filter eignen sich die Auswahl der Datenbanken, falls mehrere betrachtet werden, fachliche Gruppierungen von Tabellen, sowie die Möglichkeit, den Zeitraum einzuschränken.
Als KPI eignen sich z.B. die “Gesamtspeicher belegt in TB”, “Wachstum des Gesamtvolumens im letzten Monat in %” oder “Anzahl neu angelegter Tabellen im letzten Quartal”. Ein Liniendiagramm eignet sich besonders, um zu erkennen, ob das Gesamtvolumen kontinuierlich oder sprunghaft wächst. Eine tabellarische Ansicht zeigt die Top-10-Tabellen nach aktuellem Wachstum und prozentualem Anstieg im Detail. Ein Balkendiagramm schließlich eignet sich gut, um Bereiche oder Teams miteinander zu vergleichen – sowohl nach absolutem Speicherverbrauch als auch nach Wachstumsdynamik. Ein Kuchendiagramm ist vor allem dann hilfreich, wenn man die Verteilung des Speicherplatzes auf wenige verschiedene Kategorien, wie Anwendungen oder Abteilungen, sichtbar machen möchte.
Fazit
Speicherplatzmonitoring wird in vielen Unternehmen noch immer unterschätzt, weil Speicher auf den ersten Blick günstig wirkt. Dabei zeigt sich: Unkontrolliertes Datenwachstum verursacht Folgekosten, schafft Sicherheitsrisiken und ist oft ein früher Hinweis auf fehlende Governance und Architekturmängel. Ein gezieltes Monitoring schafft die nötige Transparenz und legt damit die Grundlage dafür, dass Datenbestände aktiv gesteuert statt nur passiv angehäuft werden. Daher stellt Storage-Monitoring einen zentralen Baustein für den sicheren, effizienten und wirtschaftlichen Betrieb von Datenplattformen dar. Wer noch keinen Überblick über den eigenen Speicherverbrauch hat, kann mit einer einfachen Abfrage auf den Metatabellen der eigenen Datenbank sofort beginnen - der erste Schritt ist kleiner als oft gedacht.
Wenn Ihnen dieser Artikel gefallen hat, lesen Sie auch gerne weitere Artikel zum Thema Datenplattformen auf unserem Blog:
Europäische Datensouveränität: Datenplattformen mit Produkten aus Europa
Von der zentralen Datenverwaltung zum Data Mesh mit Snowflake
Snowflake & Snowalert: Vertrauen ist gut – Monitoring ist besser
Wenn Sie auf der Suche nach einer passenden Datenplattform für Ihr Unternehmen sind, sprechen Sie uns gerne an - wir unterstützen Sie bei der Auswahl und Umsetzung geeigneter Lösungen.

