Nach den ersten durch Kubelet gestarteten Containern in Teil 1 geht es nun an die Einrichtung des API-Servers. Warum? YAML-Dateien mit Deployment-Descriptoren manuell auf die Worker-Nodes zu kopieren ist natürlich nicht das Zielbild. Wir wollen eine zentrale API bereitstellen, mit der wir per REST oder CLI (kubectl) interagieren können und welche die Orchestrierung mehrerer Worker-Nodes übernimmt. In diesem Blog-Post werden wir also das Setup um einen Master-Node mit API-Server sowie einen zweiten Worker-Node erweitern.
Einordnung in die Architektur
Zur Erinnerung: Kubelet läuft lokal auf jedem Worker-Node und verwaltet und überwacht die lokal laufenden Container. Es wird immer versucht, den Zielzustand wiederherzustellen. Bisher haben wir den Zielzustand (also die Pod-Spezifikationen) als YAML-Dateien in einem Ordner hinterlegt. Im "echten" Cluster-Betrieb bekommt das Kubelet diese Informationen über den API-Server, über den die Kommunikation aller Komponenten läuft. Gespeichert wird der Zustand des Clusters (also u. a. die Pod-Spezifikationen) in dem etcd-Datastapiore. Übrigens: Nur der API-Server hat Zugriff auf das etcd, alle anderen Komponenten können die Zustandsinformationen nur über den API-Server abrufen oder verändern.
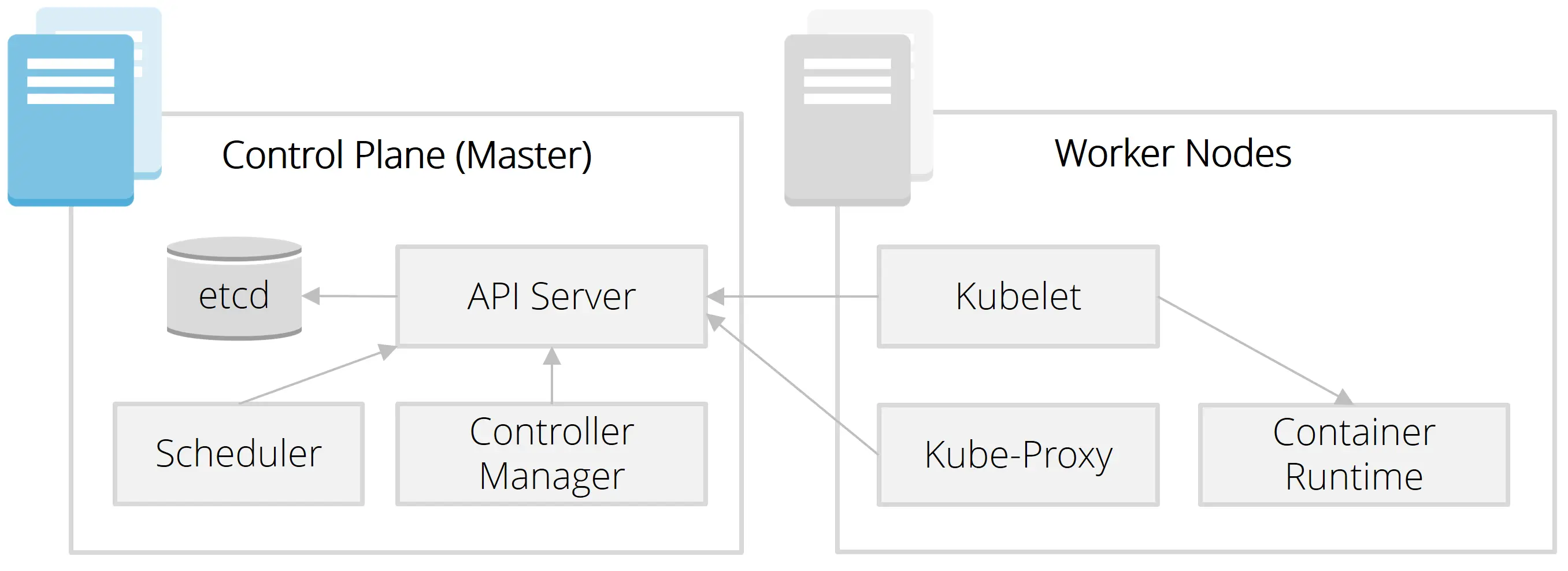
Installation des API-Servers
Zunächst brauchen wir eine zweite virtuelle Maschine, die unser Master-Node wird.
PROJECT="k8s-blogpost"
ZONE="europe-west3-c"
gcloud compute instances create master \
--project=$PROJECT \
--zone=$ZONE \
--machine-type=n1-standard-2 \
--scopes=https://www.googleapis.com/auth/devstorage.read_only,https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring.write,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/trace.append \
--image=ubuntu-minimal-1804-bionic-v20190403 \
--image-project=ubuntu-os-cloudWir installieren auch auf diesem Master-Node Docker, um den etcd-Datastore als Docker-Container zu starten. Das vereinfacht das Setup, wäre aber nicht zwingend notwendig.
# connect via ssh or use web shell
gcloud compute --project $PROJECT ssh --zone $ZONE "master"
# install docker
sudo apt-get update
sudo apt-get install apt-transport-https ca-certificates curl software-properties-common jq
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt-get update
sudo apt install docker-ce=18.06.3~ce~3-0~ubuntuFolgende Befehle starten den etcd-Datastore als Docker-Container:
mkdir etcd-data
sudo docker run -d --volume=$PWD/etcd-data:/default.etcd --net=host quay.io/coreos/etcdAnschließend gilt es, das Binary des API-Servers herunterzuladen und zu starten. Damit sich der Worker-Node auch mit dem Master-Node verbinden kann, muss der API-Server auf der internen IP-Adresse Verbindungen akzeptieren (standardmäßig nur 127.0.0.1 / localhost).
wget https://storage.googleapis.com/kubernetes-release/release/v1.13.5/bin/linux/amd64/kube-apiserver
chmod +x kube-apiserver
MASTER_IP=$(hostname -i)
sudo ./kube-apiserver --etcd-servers=http://127.0.0.1:2379 \
--service-cluster-ip-range=10.0.0.0/16 \
--insecure-bind-address=$MASTER_IP \
--admission-control=Achtung: Wir deaktivieren hier alle Admission Controller, um einen schnellen technischen Durchstich zu erreichen. Das würde man in einem nächsten Iterationsschritt direkt wieder ändern, denn Admission Controller sind - vereinfacht gesagt - Plugins, über die viele Security-Funktionen in Kubernetes realisiert sind (siehe hier).
Damit sich die Worker-Nodes mit dem API-Server verbinden können, müssen wir noch eine kubeconfig-Datei generieren. Diese muss anschließend auf alle Worker-Nodes kopiert werden. Sie enthält hier im Wesentlichen die IP-Adresse des API-Servers, mit dem sich Kubelet verbindet (statt dem Lesen von Manifest-Dateien aus dem Ordner).
cat << EOF > $PWD/master-kubeconfig.yaml
kind: Config
clusters:
- name: local
cluster:
server: http://$MASTER_IP:8080
users:
- name: kubelet
contexts:
- context:
cluster: local
user: kubelet
name: kubelet-context
current-context: kubelet-context
EOF
cat $PWD/master-kubeconfig.yamlKubelet mit dem API-Server verbinden
Auf dem Worker-Node müssen wir kubelet noch mal beenden und mit angepassten Parametern erneut starten:
# copy kubeconfig to worker node
# ssh into the worker node and run
sudo rm -R kubelet-manifests/
sudo ./kubelet --kubeconfig=$PWD/master-kubeconfig.yamlUm Verwirrungen zu vermeiden, löschen wir auch den Manifest-Ordner. Nach max. 20 Sekunden sollten bestehende Container entfernt werden, denn der etcd-Datastore ist noch leer, d. h. es sind noch keine Pod-Spezifikationen hinterlegt.
$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMESPods deployen über den API-Server
Der API-Server stellt eine REST-API bereit, die sich auch mittels curl aufrufen lässt. Folgender Befehl zeigt die registrierten Nodes an ($MASTER_IP muss auf die IP-Adresse des Master-Nodes auflösen):
$ curl http://$MASTER_IP:8080/api/v1/nodes | jq .
{
"kind": "NodeList",
"apiVersion": "v1",
"metadata": {
"selfLink": "/api/v1/nodes",
"resourceVersion": "156"
},
"items": [
{
"metadata": {
"name": "worker1",
...Als Entwickler wird man jedoch selten direkt auf die REST-API zugreifen. Das Kommandozeilen-Werkzeug "kubectl" bietet hier deutlich mehr Komfort und übernimmt im Hintergrund die Kommunikation mit der REST-API. Dafür ist auch eine kubeconfig-Datei notwendig. Die Befehle lassen sich von beliebigen Rechnern aus absetzen, sofern eine Netzwerkverbindung zum API-Server besteht. Wir nutzen hier einfach den Master-Node.
Installation auf dem Master-Node basierend auf der offiziellen Dokumentation:
sudo apt-get update && sudo apt-get install -y apt-transport-https
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
echo "deb https://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee -a /etc/apt/sources.list.d/kubernetes.list
sudo apt-get update
sudo apt-get install -y kubectlFolgendes kubectl-Kommando entspricht dem obigen curl-Request:
$ kubectl get nodes --kubeconfig master-kubeconfig.yaml
NAME STATUS ROLES AGE VERSION
worker1 Ready 21m v1.13.5Um den nginx-Pod zu deployen, legen wir zunächst die YAML-Datei an und schicken sie anschließend zum API-Server.
cat << EOF > $PWD/nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
nodeName: worker1
containers:
- name: nginx
image: nginx:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: http
protocol: TCP
restartPolicy: Always
EOF
$ kubectl apply -f nginx.yaml --kubeconfig master-kubeconfig.yaml
pod/nginx createdWichtig: Wenn man das Attribut "nodeName" weglässt, bleibt der Pod im Status "Pending", da keine Zuordnung zu einem Worker-Node erfolgt ist. Im nächsten Blog-Post fügen wir an dieser Stelle den Scheduler ein, der dieses Attribut gemäß der aktuellen Ressourcen-Auslastung füllt. Zunächst müssen wir die Zuordnung also manuell über das Attribut in der YAML-Datei vornehmen.
Mit folgendem Befehl können wir das Ergebnis kontrollieren:
$ kubectl get pods --kubeconfig master-kubeconfig.yaml -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 3s 172.17.0.2 worker1Ein zweiter Worker-Node
Um das Setup vollständig auszubauen, installieren wir noch einen zweiten Worker-Node gemäß der Anleitung aus dem ersten Blog-Post (LINK EINFÜGEN) und obiger Konfiguration des Kubelets. Als Namen verwenden wir "worker2". Sobald Kubelet gestartet ist, registriert sich der zweite Worker-Node beim API-Server:
$ kubectl get nodes --kubeconfig master-kubeconfig.yaml
NAME STATUS ROLES AGE VERSION
worker1 Ready 36m v1.13.5
worker2 Ready 63s v1.13.5Wenn man in der Pod-Spezifikation nun das Attribute "nodeName" auf "worker2" ändert, wird der Pod auf dem zweiten Node gestartet und auf dem ersten Node beendet.
cat << EOF > $PWD/nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
nodeName: worker2
containers:
- name: nginx
image: nginx:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: http
protocol: TCP
restartPolicy: Always
EOF
# delete previous pod
$ kubectl delete -f nginx.yaml --kubeconfig master-kubeconfig.yaml
pod "nginx" deleted
# create new pod
$ kubectl apply -f nginx.yaml --kubeconfig master-kubeconfig.yaml
pod/nginx created
$ kubectl get pods --kubeconfig master-kubeconfig.yaml -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 9s 172.17.0.2 worker2Wie geht es weiter?
Im dritten Blog-Post konfigurieren wir den Scheduler, der die Zuordnung von Pods zu Nodes aufgrund der aktuellen Ressourcen-Auslastung und weiteren Restriktionen vornimmt.
Sie sind Software-Entwickler, DevOps-Engineer oder IT-Architekt und möchten Kubernetes Hands-On im Rahmen eines Seminars oder Workshops kennenlernen? Zögern Sie nicht, uns zu kontaktieren. Mehr zum Thema Cloud.