
In einem vorherigen Blogbeitrag habe ich Continue präsentiert – eine Open-Source-Alternative zu Github Copilot, die maximale Flexibilität bei der Wahl von LLM-Providern bot. Continue wurde allerdings kürzlich von Cursor (das wiederum von SpaceX erworben wurde) akquiriert und wird nicht mehr aktiv gewartet.
Glücklicherweise gibt es mit OpenCode eine Open-Source-Alternative zu Tools wie GitHub CoPilot, Codex oder Claude Code. Mit OpenCode können wir unseren eigenen KI-Coding-Assistenten lokal und datenschutzkonform betreiben. In diesem Blogbeitrag wollen wir uns diesen einmal genauer ansehen.
Terminal-first
Als Github CoPilot und Continue erschienen, war es wichtig, wie gut sie sich als Plugins in bestehende IDEs wie VS Code einbetten: Geöffnete Dateien oder selektierten Codezeilen können als Kontext an das Large Language Modell übergeben werden.
Die Leistung von LLMs ist seitdem deutlich gestiegen: Sie können deutlich besser programmieren und Werkzeuge aufrufen. Anforderungen werden in einem Eingabefeld in der Seitenleiste beschrieben und Agenten können Änderungen planen, an vielen Dateien vornehmen und diese dann mit der Ausführung von Compilern, Tests usw. verifizieren.
OpenCode versucht, diesen neuen Möglichkeiten Rechnung zu tragen, indem es einen anderen Ansatz verfolgt: OpenCode ist Terminal-First, das bedeutet, es gibt OpenCode als CLI, die in jedem Terminal (auch innerhalb einer IDE) ausgeführt werden kann. In diesem ist dann auch ein Eingabefeld zum Chat mit dem KI-Assistenten sowie Möglichkeiten zur Steuerung der Agenten.
Daten-Souveränität
OpenCode arbeitet grundsätzlich mit und an Dateien auf unserem Computer. Im Allgemeinen wird das ein Ordner für ein Projekt sein, typischerweise ein Git-Repository.
OpenCode speichert Code oder Kontextdaten nicht – die gesamte Verarbeitung erfolgt lokal oder durch direkte API-Aufrufe an den AI-Anbieter der Wahl. Solange wir einen Anbieter unseres Vertrauens oder ein internes AI-Gateway verwenden, können wir OpenCode souverän nutzen und behalten die Hoheit über unsere Daten.
Die einzige Ausnahme ist die optionale Funktion /share zum Teilen von Gesprächen: Wenn diese aktiviert wird, werden die Konversation und zugehörige Daten an OpenCode übertragen. Diese Informationen lassen sich in der Dokumentation nachlesen. Standardmäßig sendet OpenCode nicht einmal Telemetry-Daten.
LLMs lokal ausführen
Um die Komplexität von APIs und deren Datenverarbeitung zu umgehen, kann man kleine LLMs auch lokal auf dem eigenen Computer ausführen. Hierfür nutze ich Ollama, ein Kommandozeilentool, mit dem sich unter Windows, Mac und Linux LLMs lokal betreiben lassen.
Mit Hilfe der Kommandozeile können wir LLMs herunterladen und ausführen. Außerdem erlaubt uns Ollama einen lokalen Server auf unserem Computer zu starten, welcher eine API bereitstellt, welche OpenCode ansprechen kann. Die Modellbibliothek von Ollama lässt sich komfortabel im Browser durchsuchen.
Ich werde ein aktuelles Open-Weight-Modell von Google DeepMind nutzen: Gemma 4. Dieses gibt es in verschiedenen Größen. Mein MacBook Pro hat 24 GB Arbeitsspeicher, deswegen habe ich mich für das Modell mit 12 Milliarden Parametern entschieden. Als Faustregel lässt sich sagen, dass eine größere Parameteranzahl in der Regel auch mehr Leistungsfähigkeit bedeutet. Ich wähle das 12 Milliarden Parameter Modell, da es gut in meinen Arbeitsspeicher passt. Dieses ist quantized etwa 7,6 GB groß. Quantization ist ein Optimierungsverfahren, bei dem die Genauigkeit der Gewichte eines Modells reduziert wird – zum Beispiel von 32-Bit auf 4-Bit Zahlen – wodurch die Dateigröße erheblich schrumpft, ohne die Qualität merklich zu beeinträchtigen. Das ermöglicht es, große Modelle auf Hardware mit begrenztem Speicher auszuführen.
Um unser Modell herunterzuladen, führe ich den Befehl ollama pull gemma4:12b im Terminal aus und Ollama lädt das Modell herunter.
Anmerkung: Es gibt das Modell auch in einer MLX-Version. MLX ist eine Laufzeitumgebung eigens für Apple-Prozessoren.
Ein lokaler Server mit Ollama
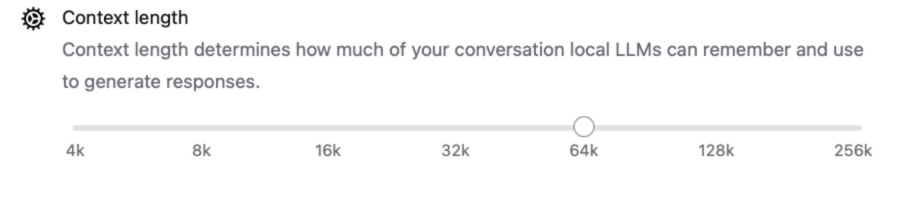
Der Ollama-Server wartet automatisch auf Anfragen. Der Server folgt der API-Spezifikation der OpenAI-Server, diese hat sich als de facto Standard etabliert. Für unseren KI-Assistenten sollten wir allerdings die Größe des Kontextfensters anpassen. Dafür gehen wir in die Einstellungen der Ollama-App, welche auf dem Mac etwa oben in der Systemleiste zu finden sind und wählen Settings. Dort können wir die Größe des Kontextfensters anpassen. Ollama empfiehlt für OpenCode mindestens 64K:
OpenCode einrichten
OpenCode ist eine Kommandozeilen-Anwendung, welche über das Terminal ausgeführt wird, dementsprechend wird sie auch über das Terminal installiert. Es gibt verschiedene Möglichkeiten zur Installation, etwa über npm oder Homebrew. Aus diesem Grund verlinke ich an dieser Stelle nur die offizielle Dokumentation.
OpenCode kann mit einer Konfigurationsdatei mit dem Namen opencode.json konfiguriert werden. Hier können wir etwa unsere Modelle und unseren Ollama-Server hinterlegen. Diese Konfiguration kann an verschiedenen Orten (etwa global oder im Projektverzeichnis) hinterlegt werden. Für unsere Zwecke werde ich sie im Projektverzeichnis ablegen. Die Konfigurationsorte sind in der Dokumentation beschrieben.
Dies ist meine opencode.json:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"name": "Ollama (local)",
"options": {
"baseURL": "http://localhost:11434/v1"
},
"models": {
"gemma4:12b": {
"name": "Gemma 4"
}
}
}
}
}Ich sage OpenCode, dass es einen OpenAI-kompatiblen Server nutzen soll und gebe das Modell an. Gemma 4 ist hier ein Alias, den ich vergeben habe, damit es bei der Modellselektion nicht unübersichtlich wird. Wenn ich OpenCode jetzt mit dem Befehl opencode starte, ist trotzdem GPT-5 als Standard ausgewählt. Um unser Gemma-4-Modell auszuwählen, geben wir /models und dann Gemma 4 ein.
Anmerkung: Ollama kann OpenCode auch direkt mit der passenden Konfiguration für Ollama über den Launch-Befehl starten.
Sicherheit vs. Autonomie
OpenCode zeichnet sich durch hohe Autonomie aus: Der AI-Agent führt Werkzeuge und Befehle standardmäßig ohne explizite Bestätigung des Benutzers aus. Diese Autonomie ermöglicht schnelle und effiziente Entwicklung, birgt aber auch Risiken – wenn das zugrunde liegende LLM einen Fehler macht oder das falsche Kommando ausführt, kann dies zu unbeabsichtigten Änderungen im Dateisystem oder in der Infrastruktur führen.
Um diese Risiken zu minimieren, wird empfohlen, OpenCode in einer isolierten Umgebung auszuführen – etwa in einer Docker Sandbox. Eine microVM bietet eine abgeschottete Laufzeitumgebung, in der OpenCode ohne Auswirkungen auf das Host-System arbeitet. Falls der AI-Agent unerwünschte Operationen ausführt, sind diese auf die VM begrenzt und können das darunterliegende System nicht beschädigen.
Docker Sandboxes bieten mittlerweile Support für OpenCode.
OpenCode Agenten
OpenCode arbeitet mit verschiedenen Agenten, die auf unterschiedliche Aufgaben spezialisiert sind. Dabei wird zwischen Primär- und Subagenten unterschieden.
Primäragenten
Primäragenten sind diejenigen, mit denen wir direkt interagieren. Mit der Tabulatortaste können wir jederzeit zwischen ihnen wechseln.
Plan
Ein eingeschränkter Agent für Planung und Analyse. Plan kann Code lesen, Änderungen vorschlagen und Pläne erstellen – aber ohne tatsächlich Dateien zu ändern oder Bash-Befehle auszuführen.
Build
Der Standard-Agent für Entwicklung. Build hat Zugriff auf alle Werkzeuge – Dateivorgänge, Bash-Befehle, alles. Wenn Sie eine Anforderung stellen, wird Build diese umsetzen.
Subagenten
Neben den Primäragenten gibt es Subagenten, die für spezielle Aufgaben zuständig sind. Sie werden entweder automatisch aufgerufen oder wir können sie im Chat mit @ erwähnen (zum Beispiel: @general help me find this bug).
General
Ein Allzweck-Subagent für komplexere Recherchen und mehrstufige Aufgaben. Er hat Zugriff auf die meisten Werkzeuge und kann eigene Sitzungen starten.
Explore
Ein spezialisierter Agent zum Durchsuchen von Codebasen. Explore hat nur lesenden Zugriff – ideal, wenn wir schnell durch Dateien navigieren oder Codezeilen finden möchten oder Fragen zu unserer Codebasis haben.
Scout
Kümmert sich um externe Dokumentation und Dependencies. Scout hat ebenfalls nur lesenden Zugriff und hilft uns, Quellcode von Bibliotheken zu untersuchen oder lokale Änderungen mit Upstream-Versionen zu vergleichen.
Es gibt noch mehr Agenten. Sie sind in der Dokumentation genauer beschrieben.
Weitere Möglichkeiten mit OpenCode
Nicht nur lokale Modelle lassen sich mit OpenCode betreiben, per LiteLLM (oder einem anderen Proxy) lassen sich auch (selbstgehostete) Modelle in der Cloud anbinden und das System auf Unternehmensebene skalieren. Das hat mein Kollege Tobias Goerke in seinem Blogbeitrag beschrieben.
Darüber hinaus lassen sich den Agenten weitere Werkzeuge und Möglichkeiten zur Verfügung stellen. So werden etwa Model Context Protocol-Server und Agent-Skills unterstützt. Außerdem können die Ausgaben von Language-Services, wie etwa Compilern, genutzt werden, um statische Codeanalyse den Agenten bereitzustellen.
Fazit
Mit einem lokalen LLM, minimaler Konfiguration und voller Kontrolle über die eigenen Daten haben wir mit Hilfe von OpenCode einen sehr mächtigen KI-Coding-Assistenten. Diese Mächtigkeit kommt insbesondere von der Autonomie der Agenten. Sie führen automatisiert Werkzeuge aus und treffen Entscheidungen. Es bedeutet auch, dass die lokalen Modelle immer mehr Fähigkeiten haben müssen, was meistens entsprechend große Modelle voraussetzt und damit die Hardwareanforderungen in die Höhe treibt. Es drängt sich der Eindruck auf, dass OpenCode insbesondere für den Betrieb mit großen Frontier-Modellen wie Claude oder ChatGPT entworfen worden ist. Insbesondere Entwickler:innen mit viel Arbeitsspeicher werden ihre Freude mit OpenCode haben.

