Sie bauen ein Data Warehouse in Snowflake auf und fragen sich, ob Sie zur Historisierung Dynamic Tables oder Stored Procedures verwenden sollten? Dieser Artikel betrachtet die Vor- und Nachteile im Detail und gibt Ihnen eine klare Empfehlung.
Bei der Erstellung eines DWHs spielt die Historisierung der Daten eine zentrale Rolle. In einem Data Warehouse haben fast alle Daten einen zeitlichen Bezug. Das ermöglicht es Auswertungen über Zeiträume zu erstellen oder Kennzahlen mit denen vom Vorjahr zu vergleichen. Dazu muss der Stand der zugrunde liegenden Daten für die betrachteten Zeitpunkte vorliegen. Typischerweise werden daher die Daten aus den Quellsystemen im Rahmen des ETL-Prozesses beim Laden in das DWH historisiert. Eine sehr verbreitete Strategie, eine vollständige Historie aufzubauen, ist Slowly Changing Dimension (SCD) Type 2. In Snowflake gibt es bisher keine vorgefertigte Funktion, die aus den Änderungen an der Quelltabelle automatisch eine SCD Type 2 Historientabelle erzeugt. In der Dokumentation von Snowflake ist jedoch ein Hinweis enthalten, wie man SCD Type 2 Tabellen sehr einfach mit Hilfe von Dynamic Tables erzeugen kann. Wir wollen uns die Vor- und Nachteile dieser Umsetzung im Vergleich zu einer eigenen Implementierung mit Stored Procedures anschauen.
Wie funktioniert Slowly Changing Dimension Type 2?
Nach der Definition von Inmon ist ein DWH “a subject-oriented, integrated, time-variant, nonvolatile collection of data in support of management’s decision-making process.“ Die Definition enthält zwei wichtige Anforderungen an die Datenspeicherung. Zum einen “nonvolatile“, also die Daten ändern sich nicht, sodass Auswertungen reproduzierbar sind. Zum anderen “time-variant“, also eine Speicherung der Daten über einen langen Zeitraum, sodass entsprechende Analysen gemacht werden können. Slowly Changing Dimension Type 2 ist eine Strategie zur Datenspeicherung, welche diese beiden Aspekte berücksichtigt.
Bei SCD Type 2 wird bei einer Änderung an einem Datensatz nicht der existierende Datensatz im DWH überschrieben, sondern es wird eine neue Version des Datensatzes mit den Änderungen geschrieben. Somit werden historische Daten bewahrt. Die verschiedenen Versionen eines Datensatzes haben dabei immer eine zeitliche Gültigkeit. Dazu werden in den Tabellen zwei Spalten DWH_VALID_FROM und DWH_VALID_TO eingefügt, die angeben, von wann bis wann diese Version gültig war.
Beispiel:
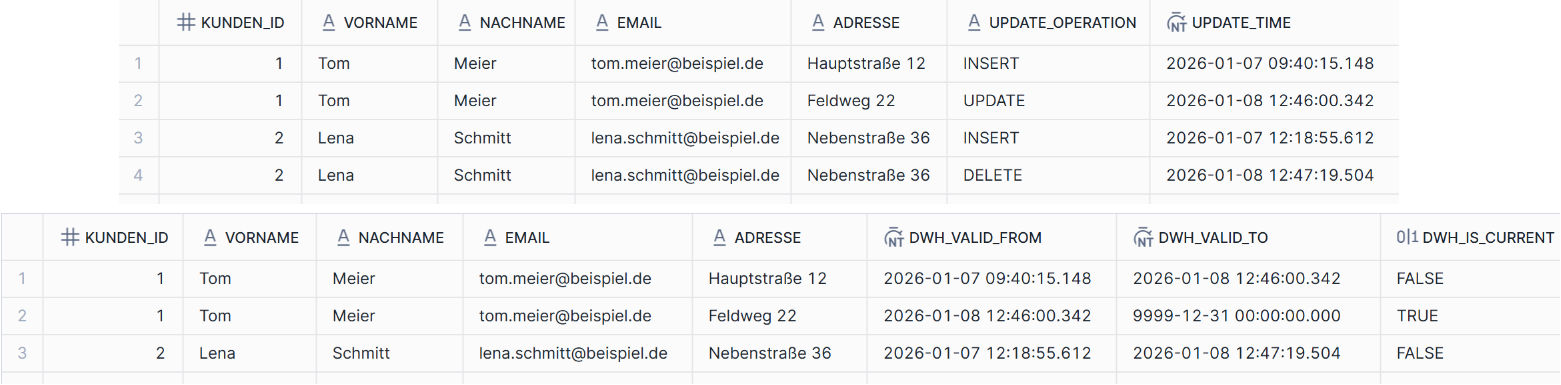
Wir bekommen aus einem Quellsystem sämtliche Änderungen an der Tabelle CUSTOMER geliefert und speichern diese im DWH in der Tabelle CUSTOMER_CHANGES. Über die Spalte UPDATE_OPERATION wird mitgeliefert, ob es sich um einen neuen Datensatz (INSERT), eine Änderung an einem bestehenden Datensatz (UPDATE) oder um eine Löschung (DELETE) handelt. Anhand der UPDATE_TIME lässt sich ablesen, wann diese Änderung stattgefunden hat.

Im Beispiel wurden nun zwei neue Kunden hinzugefügt, sodass die SCD Type 2 Tabelle CUSTOMER_HISTORY folgendermaßen aussehen würde. Die UPDATE_TIME wird dabei in DWH_VALID_FROM übernommen.

Angenommen der Kunde Tom Meier zieht um, was eine Adressänderung zur Folge hat und die Kundin Lena Schmitt kündigt. Wir bekommen folgende Änderungen geliefert:

Wenn diese Änderungen in die CUSTOMER_HISTORY eingepflegt werden, wird eine zweite Version des Datensatzes für den Kunden Tom Meier angelegt mit der aktualisierten Adresse. Die erste Version wird dann abterminiert mit dem Zeitpunkt, ab dem die aktualisierte gültig geworden ist. Für die Kundin Lena Schmitt wurde im Quellsystem der Datensatz gelöscht. In der Historientabelle wird der Datensatz aber nicht gelöscht. Stattdessen wird der aktuelle Datensatz abterminiert und auf ungültig gesetzt. Somit ist später für Auswertungen erkennbar, in welchem Zeitraum sie Kundin war.

Implementierung SCD Type 2 in Snowflake mit Dynamic Tables
Dynamic Tables sind eine spezielle Art von Tabellen in Snowflake, die über eine Abfrage definiert werden und von Snowflake automatisch aktualisiert werden. Bei der Definition der Dynamic Table muss eine Zielaktualität angegeben werden, z.B. '1 Minute'. Snowflake überwacht dann die Basistabellen, aus denen in der Abfrage selektiert wird und aktualisiert automatisch im vorgegebenen Intervall die Dynamic Table, sodass die Änderungen aus den Basistabellen sich dort auch widerspiegeln. Dabei wird die Abfrage nur für die Datensätze ausgeführt, die sich in den Basistabellen verändert haben. Das Ergebnis der Abfrage wird also inkrementell berechnet und in die Dynamic Table eingefügt (für weitere Details s. hier). Dies ist insbesondere vorteilhaft, wenn die Abfrage zur Erstellung der Tabelle sehr komplex ist, die Datenmengen sehr groß sind oder ein kleines Aktualisierungsintervall gefordert ist. So muss nicht jedes Mal die gesamte Tabelle mit allen Datensätzen aufwendig berechnet werden, sondern nur die Datensätze, bei denen sich Änderungen ergeben haben. So kann Rechenzeit gespart werden, was für Anwendungen mit nahezu Echtzeitverarbeitung entscheidend ist.
Wie können wir nun Dynamic Tables einsetzen, um SCD Type 2 Tabellen zu erstellen? Wir nutzen die Tabelle CUSTOMER_CHANGES aus dem vorherigen Beispiel als Basistabelle und bauen die CUSTOMER_HISTORY als Dynamic Table darüber. In einer Window-Function betrachten wir alle Datensätze zu einem Kunden, sortiert nach UPDATE_TIME. Mit LEAD() können wir auf den nachfolgenden Datensatz zugreifen und definieren den Endzeitpunkt der Gültigkeit als UPDATE_TIME des nachfolgenden. Wenn es keinen Nachfolger mehr gibt, handelt es sich um den aktuellen Datensatz. In dem Fall wird DWH_VALID_TO auf den Maximalwert und das Kennzeichen DWH_IS_CURRENT auf TRUE gesetzt. Damit bei einer Löschung keine zusätzliche Version des Datensatzes erzeugt wird, die ab dann gültig ist, werden die Delete-Operationen am Ende gefiltert.
CREATE OR REPLACE DYNAMIC TABLE CUSTOMER_HISTORY(
KUNDEN_ID NUMBER,
VORNAME VARCHAR,
NACHNAME VARCHAR,
EMAIL VARCHAR,
ADRESSE VARCHAR,
DWH_VALID_FROM TIMESTAMP_NTZ,
DWH_VALID_TO TIMESTAMP_NTZ,
DWH_IS_CURRENT BOOLEAN
) TARGET_LAG = '1 MINUTE' REFRESH_MODE = AUTO INITIALIZE = ON_CREATE WAREHOUSE = TEST_WH
as
with CTE_SCD as (
SELECT KUNDEN_ID,
VORNAME,
NACHNAME,
EMAIL,
ADRESSE,
UPDATE_TIME as DWH_VALID_FROM,
CASE
WHEN LEAD(UPDATE_TIME) OVER (PARTITION BY KUNDEN_ID ORDER BY UPDATE_TIME) IS NULL
THEN to_timestamp_NTZ('9999-12-31','YYYY-MM-DD')
ELSE LEAD(UPDATE_TIME) OVER (PARTITION BY KUNDEN_ID ORDER BY UPDATE_TIME)
END as DWH_VALID_TO,
CASE
WHEN LEAD(UPDATE_TIME) OVER (PARTITION BY KUNDEN_ID ORDER BY UPDATE_TIME) IS NULL
THEN TRUE
ELSE FALSE
END as DWH_IS_CURRENT,
UPDATE_OPERATION
FROM CUSTOMER_CHANGES
)
SELECT * EXCLUDE UPDATE_OPERATION
FROM CTE_SCD
WHERE UPDATE_OPERATION <> 'DELETE';Auf diese Weise können wir schnell mit einer einfachen Programmierung eine vollständige SCD Type 2 Historientabelle erzeugen, wie es im Beispiel oben erklärt wurde. Sobald wir weitere Änderungen aus dem Quellsystem geliefert bekommen und diese in CUSTOMER_CHANGES einfügen, erweitert sich unsere Historientabelle CUSTOMER_HISTORY inkrementell innerhalb von einer Minute automatisch:
Diese Umsetzung erfordert jedoch, dass wir alle Änderungen weiterhin in der Basistabelle speichern, obwohl die Informationen jetzt ebenfalls in der CUSTOMER_HISTORY enthalten sind. Würden wir Einträge aus der Basistabelle löschen, könnte die Dynamic Table nicht neu initialisiert werden. Eine neue Initialisierung wäre unter anderem notwendig, wenn sich das Tabellenschema ändert, weil z.B. eine neue Spalte “Telefonnummer” hinzugekommen ist. Dann müsste die Abfrage angepasst und die Dynamic Table einmal vollständig neu erstellt werden. Das würde einem Neuaufbau der gesamten Historie entsprechen. Wenn aber nun zuvor Datensätze aus der Basistabelle gelöscht wurden, würden diese Informationen in der Historie fehlen. Die Daten werden also doppelt gespeichert, was zu zusätzlichen Speicherkosten führt, die in der Regel jedoch vernachlässigbar sind. Man sollte außerdem im Hinterkopf behalten, dass bei häufigen Änderungen in einer Tabelle die Historie schnell wächst und eine neue Initialisierung der Dynamic Table mit der Zeit immer aufwendiger wird. Das gezeigte Verfahren funktioniert zusätzlich nur mit einem Delta-Load der Änderungen. Sollte es mal zu Problemen mit der Lieferung der Änderungen kommen und es ist eine vollständige Synchronisierung mit der Tabelle aus dem Quellsystem erforderlich (Full-Load), dann würden neue Versionen für alle Datensätze angelegt werden unabhängig davon, ob es tatsächlich Änderungen gegeben hat. So könnten zwei Versionen für einen Kunden entstehen, die den exakt gleichen Datenstand darstellen, was nicht mehr SCD Type 2 konform wäre.
Implementierung SCD Type 2 in Snowflake als Stored Procedure
Wie wir gesehen haben, lässt sich SCD Type 2 mit Dynamic Tables zwar einfach und schnell umsetzen, jedoch bringt dieser Ansatz auch Nachteile mit sich. Wir wollen uns daher eine eigene Implementierung im Vergleich anschauen. Dazu haben wir in Snowflake eine Stored Procedure erstellt, welcher man die Änderungs- und Historientabelle sowie den Primärschlüssel übergibt. Zusätzlich kann man noch angeben, ob es sich um einen Delta-Load oder Full-Load handelt:
CALL CREATE_SCD2_HISTORY(
SOURCE_SCHEMA_NAME => 'STAGING', -- Schema der Tabelle mit Änderungen
SOURCE_TABLE_NAME => 'CUSTOMER_CHANGES', -- Tabelle mit Änderungen
TARGET_SCHEMA_NAME => 'HIST', -- Schema der Historientabelle
TARGET_TABLE_NAME => 'CUSTOMER_HISTORY', -- Historientabelle
PRIMARY_KEY => 'KUNDEN_ID' -- Primärschlüssel für den Merge
IS_FULL_LOAD => FALSE, -- Delta- oder Full-Load
);Die Prozedur erstellt dann automatisch die Historientabelle und lässt sich grob in zwei Abschnitte unterteilen. Im ersten Abschnitt wird das Tabellenschema der Historientabelle mit dem der Änderungstabelle synchronisiert und im zweiten Abschnitt werden die Daten per SQL-Merge in die Historientabelle geschrieben. Um die Tabellenschemata abzugleichen wird ein SQL-Statement generiert, welches eine temporäre Tabelle erstellt, die die Spalten und Datentypen der Änderungs- und Historientabelle enthält. Die Daten werden dabei aus dem INFORMATION_SCHEMA.COLUMNS gelesen und per Full Outer Join gegenübergestellt. Mit dieser Tabelle lässt sich nun bestimmen, wo es Abweichungen zwischen den Spalten und somit Anpassungsbedarf bei der Historientabelle gibt.
TMP_COLUMN_COMPARE_SQL := '
CREATE OR REPLACE TEMPORARY TABLE ' || TARGET_SCHEMA_NAME || '.TMP_COLUMN_COMPARE_' || TARGET_TABLE_NAME || ' as
SELECT source.COLUMN_NAME as SOURCE_COLUMN_NAME,
target.COLUMN_NAME as TARGET_COLUMN_NAME,
source.DATA_TYPE as SOURCE_DATA_TYPE,
target.DATA_TYPE as TARGET_DATA_TYPE,
source.CHARACTER_MAXIMUM_LENGTH as SOURCE_CHARACTER_MAXIMUM_LENGTH,
target.CHARACTER_MAXIMUM_LENGTH as TARGET_CHARACTER_MAXIMUM_LENGTH,
source.NUMERIC_PRECISION as SOURCE_NUMERIC_PRECISION,
target.NUMERIC_PRECISION as TARGET_NUMERIC_PRECISION,
source.NUMERIC_SCALE as SOURCE_NUMERIC_SCALE,
target.NUMERIC_SCALE as TARGET_NUMERIC_SCALE
FROM (
SELECT *
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = \'' || SOURCE_SCHEMA_NAME || '\'
AND TABLE_NAME = \'' || SOURCE_TABLE_NAME || '\'
) source
FULL OUTER JOIN (
SELECT *
FROM INFORMATION_SCHEMA.COLUMNS ISC
WHERE TABLE_SCHEMA = \'' || TARGET_SCHEMA_NAME || '\'
AND TABLE_NAME = \'' || TARGET_TABLE_NAME || '\'
) target
ON source.COLUMN_NAME = target.COLUMN_NAME
WHERE source.COLUMN_NAME NOT LIKE \'DWH_%\' -- DWH-Spalten bei Schemasynchronisation ignorieren
;'
;Basierend auf dieser Tabelle erstellen wir ein Resultset inklusive Cursor, mit dem wir in einer For-Schleife auf die einzelnen Datensätze aus der Tabelle zugreifen können. In der Schleife werden dann SQL-Statements generiert, die die Synchronisation des Tabellenschemas durchführen. Hier z.B. werden Statements generiert, um neue Spalten aus der Änderungstabelle in der Historientabelle anzulegen:
COLUMN_COMPARE_RS := (EXECUTE IMMEDIATE :SELECT_COLUMN_COMPARE_SQL);
LET c1 CURSOR FOR COLUMN_COMPARE_RS;
FOR record IN c1 DO
IF(record.SOURCE_COLUMN_NAME is NOT NULL AND -- Spalte ist in Änderungstabelle enthalten
record.TARGET_COLUMN_NAME is NULL) -- Spalte ist nicht in Historientabelle
THEN
-- Generiere SQL Statements für neue Spalten in der Quelltabelle, die in der Zieltabelle angelegt werden müssen
SYNC_SQL := COALESCE(SYNC_SQL, '') || 'ALTER TABLE ' || TARGET_SCHEMA_NAME || '.' || TARGET_TABLE_NAME || '
ADD COLUMN ' || record.SOURCE_COLUMN_NAME || ' ' || record.SOURCE_DATA_TYPE || ';'
;
END IF;
END FOR;Analog werden die SQL-Statements für die Anpassung der Datentypen generiert und ausgeführt, sodass am Ende die Historientabelle synchron zur Änderungstabelle ist. Lediglich gelöschte Spalten bleiben in der Historientabelle enthalten und werden nicht gelöscht, damit die historischen Informationen nicht verloren gehen.
Im zweiten Abschnitt werden dann die Daten aus der Änderungstabelle in die Historientabelle eingefügt. Dies erfolgt in drei Schritten. Als Erstes müssen in der Historientabelle alle aktuellen Versionen der Datensätze bestimmt werden, für die ein Update oder Delete geliefert wurde. Diese Versionen müssen dann im zweiten Schritt abterminiert werden. Als Letztes werden dann die aktualisierten und die neu erzeugten Datensätze in die Historientabelle eingefügt. Die SQL-Statements dafür werden generiert aus den Aufrufparametern der Stored Procedure und zusätzlichen Variablen, die zu Beginn erstellt wurden. So enthält beispielsweise die Variable COLUMNS_RAW alle Spaltennamen ohne Präfix, COLUMNS_WITH_SOURCE alle Spalten mit “source.“ als Präfix und COLUMNS_FOR_MATCHING die Join-Bedingung. Die Join-Bedingung wird aus dem Parameter PRIMARY_KEY generiert und würde in unserem Beispiel “source.KUNDEN_ID = target.KUNDEN_ID“ entsprechen.
Wenn der Parameter IS_FULL_LOAD auf “TRUE” steht, passen wir den ersten Schritt an und bestimmen dort nur die Datensätze, bei denen es auch tatsächlich eine Änderung gegeben hat, indem wir einen Hash über alle Spalten bestimmen und vergleichen. So kann mit diesem Verfahren auch ein Full-Load gemacht werden, ohne dass zwei Versionen des gleichen Datenstandes entstehen.
/* 1. Prüfe, ob beim Delta Load ein Delete oder Update erfasst wurde. Selektiere alle Datensätze aus der Historientabelle,
für die das zutrifft, da diese im nächsten Schritt abterminiert werden müssen. */
TEMP_TABLE_SQL :=
'CREATE OR REPLACE TEMPORARY TABLE ' || TARGET_SCHEMA_NAME || '.TMP_' || TARGET_TABLE_NAME || '_UPDATES as
SELECT target.*,
source.UPDATE_TIME
FROM ' || TARGET_SCHEMA_NAME || '.' || TARGET_TABLE_NAME || ' target
INNER JOIN (
SELECT ' || COLUMNS_RAW || ',
UPDATE_OPERATION
FROM ' || SOURCE_SCHEMA_NAME || '.' || SOURCE_TABLE_NAME || '
WHERE UPDATE_OPERATION in (\'UPDATE\', \'DELETE\')
) source
ON ' || COLUMNS_FOR_MATCHING || '
AND target.DWH_VALID_FROM <> source.UPDATE_TIME
WHERE target.DWH_IS_CURRENT = TRUE;'
;
execute immediate :TEMP_TABLE_SQL;
/* 2. Terminiere alle aktuellen Datensätze in der Historientabelle ab, für die im ersten Schritt ein Update oder Delete ermittelt wurde */
UPDATE_SQL := 'UPDATE ' || TARGET_SCHEMA_NAME || '.' || TARGET_TABLE_NAME || ' target
SET DWH_VALID_TO = source.UPDATE_TIME,
DWH_IS_CURRENT = FALSE
FROM ' || TARGET_SCHEMA_NAME || '.TMP_' || TARGET_TABLE_NAME || '_UPDATES source
WHERE ' || COLUMNS_FOR_MATCHING || '
AND target.DWH_IS_CURRENT = TRUE;'
;
execute immediate :UPDATE_SQL;
/* 3. Füge alle Datensätze aus der Eingabetabelle in die Historientabelle ein, für die es keinen aktuellen Datensatz dort gibt. */
MERGE_SQL := 'INSERT INTO ' || TARGET_SCHEMA_NAME || '.' || TARGET_TABLE_NAME ||
'(' || COLUMNS_RAW || ')
SELECT ' || COLUMNS_WITH_SOURCE || '
FROM ' || SOURCE_SCHEMA_NAME || '.' || SOURCE_TABLE_NAME || ' source
WHERE UPDATE_OPERATION in (\'UPDATE\', \'INSERT\')
AND NOT EXISTS (
SELECT 1
FROM ' || TARGET_SCHEMA_NAME || '.' || TARGET_TABLE_NAME || ' target
WHERE ' || COLUMNS_FOR_MATCHING || '
AND target.DWH_IS_CURRENT = TRUE
);'
;
execute immediate :MERGE_SQL;Diese Art der Implementierung ist deutlich aufwendiger und komplexer, bietet dafür aber auch einige Vorteile. Zum einen können die Daten aus der Änderungstabelle nach dem Merge in die Historientabelle gelöscht werden. Zum anderen muss bei Schemaänderungen nicht die gesamte Historie neu berechnet werden. Stattdessen werden wenig aufwendige DDL-Operationen angewendet und anschließend kann der Merge wieder durchgeführt werden. Auch ist es möglich, zwischen Delta- und Full-Load zu unterscheiden.
Zusammenfassung
Dynamic Tables sind eine Option, um schnell und ohne großen Aufwand SCD Type 2 umzusetzen. Sie erfordern durch die inkrementelle Berechnung weniger Rechenkapazitäten und können daher auch gut für die Erstellung komplexerer Dimensionstabellen genutzt werden. Zusätzlich ermöglichen sie auch sehr hohe Aktualisierungsfrequenzen und sind somit für eine Echtzeitverarbeitung geeignet. Allerdings erfordern Dynamic Tables einen manuellen Anpassungsbedarf bei Schemaänderungen und unterstützen keine Unterscheidung zwischen Full- und Delta-Load. Der Ansatz über die Stored Procedures besitzt diese Schwächen nicht. Er erfordert einen höheren initialen Aufwand bei der Implementierung, aber bedarf im laufenden Betrieb, auch bei Schemaänderungen, keine manuellen Anpassungen. Die Stored Procedures bieten also eine bessere Automatisierung des Prozesses, benötigen aber durch die komplexere Umsetzung mehr Rechenkapazitäten. Ein weiterer Vorteil ist, dass man die Stored Procedure in andere SQL Systeme migrieren kann. Es muss dann die Syntax und die Elemente von Snowflake-Scripting auf das entsprechende System geändert werden. Das ist bei Dynamic Tables nicht so einfach. Wenn dort die zugrundeliegende Abfrage übertragen wird in ein System, welches keine Dynamic Tables bietet, würde das dazu führen, dass jedes Mal die gesamte Historie aufgebaut wird.

Fazit und Ausblick
Unsere Empfehlung aus der Praxis: Nutzen Sie Dynamic Tables, wenn Sie eine hohe Aktualisierungsfrequenz benötigen, sich Schemas nur selten ändern und ein gelegentlicher Neuaufbau akzeptabel ist. Nutzen Sie eine Implementierung mit Stored Procedures, wenn Sie Schema Änderungen erwarten, ein Wechsel zwischen Full- und Delta Load erforderlich ist und die Lösung portabel in andere Dialekte sein soll.
Beide Verfahren können auch kombiniert werden.
Wenn Sie Interesse haben, ein Data Warehouse aufzubauen, ob in Snowflake oder On-Premise, sprechen Sie uns gerne an. Wir bieten auch Schulungen in den Themenfeldern Grundlagen von Data Warehousing und Cloud Data Warehouse an.
Interesse geweckt? Entdecken Sie unsere Blogreihe zu Data Science mit Snowflake!