
Wann lohnt sich der Einsatz von KI-Agenten und was genau zeichnet sie aus? Diese Fragen stehen im Raum, denn das Potenzial dieser Technologie ist enorm: Sie können komplexe Aufgaben vollkommen eigenständig lösen. Zum Beispiel konnte ein KI-Agent über 6 Mal so viele Coding-Aufgaben erfolgreich lösen wie ein normales Large Language Model(LLM) [1]. Wir machen in unseren Projekten ähnliche Erfahrungen
Um dieses Potenzial gezielt zu nutzen, ist es entscheidend, die grundlegenden Merkmale eines Agenten zu verstehen. In diesem Blogartikel klären wir sie und zeigen wie KI-Agenten unterschiedliche Aufgabenstellungen lösen können. Da dieses Thema noch relativ neu ist, existiert bislang keine einheitliche Definition. Dennoch wird eine Orientierungshilfe angeboten, die einen ersten Einblick in die vielfältigen Funktionalitäten dieser Systeme ermöglicht. Um zu verstehen, was einen LLM-Agenten ausmacht, ist es zunächst sinnvoll, eine einfachere Alternative zu betrachten: LLM-basierte Workflows.
Level 1: LLM-Basierte Workflows
LLM-basierte Workflows sind vordefinierte Programmabläufe, in deren Verlauf LLMs eingesetzt werden. Oft wird ein LLM mit externer Funktionalität erweitert, da es trotz umfangreicher Fähigkeiten enge Grenzen und kein unternehmensspezifisches Wissen hat. Ein klassisches Beispiel hierfür ist der Retrieval Augmented Generation (RAG)-Workflow. Dieser wird eingesetzt, um das Wissen eines LLMs anhand einer Dokumentenbasis, beispielsweise interne Confluence-Seiten, zu erweitern. Dadurch kann das LLM auch Fragen zu internen Prozessen und Vorgaben beantworten (Beispiel: “Korrigiere diesen Text mit Blick auf unsere CI-Richtlinien”).

In diesem Ablauf läuft jeder Schritt in der vordefinierten Reihenfolge ab, unabhängig davon welche Anfrage der Nutzer stellt oder welche Dokumente gefunden werden. Für Szenarien in denen Anfragen basierend auf einer Wissensbasis beantwortet werden sollen, funktioniert RAG sehr gut und eignet sich als erstes KI-Projekt mit eigenen Daten.
Level 2: Agentische LLM-Workflows
Klassische LLM-Workflows sind für viele Anwendungsbereiche die richtige Lösung. Dennoch weisen sie eine entscheidende Limitation auf: Der Workflow passt sich weder an die Eingabe des Nutzers, noch an wechselnde Rahmenbedingungen an. In Bereichen, in denen diese Faktoren sehr vielfältig sind, ist es nahezu unmöglich, einen herkömmlichen Ablauf zu entwickeln, der alle Eventualitäten abdeckt – jedenfalls nicht ohne erheblichen Mehraufwand (Beispiel: “Korrigiere diesen Text und stelle möglichst Querverweise zu allen schon vorliegenden Texten her”).
Am Beispiel des zuvor beschriebenen RAG-Prozesses werden diese Herausforderungen deutlich: Wird fälschlicherweise keine geeignete Quelle gefunden oder erfordert eine komplexe Anfrage idealerweise mehrere aufeinanderfolgende Suchvorgänge, stößt der fest definierte Ablauf schnell an seine Grenzen. Zwar ließe sich ein mehrstufiger Suchprozess in den klassischen Workflow integrieren, doch würde dies bei einfacheren Anfragen zu unnötigen Wartezeiten und hohem Ressourcenverbrauch führen. Um diese Probleme zu vermeiden, ist ein dynamischer Ablauf hilfreich, der sich flexibel an die spezifischen Anforderungen der Aufgabe und an die Rahmenbedingungen anpasst. Das LLM selbst übernimmt dabei eine zentrale Steuerungsfunktion im Workflow. Es entscheidet zum Beispiel, ob die vorhandenen Informationen für eine fundierte Antwort ausreichen oder ob eine weitere Suche gestartet werden muss. Wissenschaftliche Studien zeigen, dass diese Art von agentischen RAG-Abläufen die Antwortqualität um durchschnittlich ca. 30% verbessern können [2].
Für die Definition von KI-Agenten orientieren wir uns an der gängigen Technik ReAct [3]:
Ein LLM-Agent ist ein System, in dem das große Sprachmodell als zentrale Denk- und Planungseinheit fungiert. Es steuert nicht nur einen festen Ablauf, sondern bewältigt eine Aufgabe dynamisch, indem es eine Kette von Entscheidungen trifft: Es analysiert das Problem, wählt eine passende Aktion aus, bewertet das Ergebnis und plant den nächsten Schritt.
Es gibt zahlreiche Möglichkeiten, wie ein LLM den Ablauf steuern kann, von der Wahl zwischen mehreren festen Abläufen an vorgegebenen Knotenpunkten bis hin zu vollständig dynamischen Abläufen, wobei im Prinzip alle Varianten denkbar sind. Diese Vielfalt führt häufig zu Diskussionen darüber, ab wann ein LLM-Workflow tatsächlich als Agent betrachtet werden kann. Es ist meist zielführender, nicht strikt zwischen einem Workflow als Agent oder Nicht-Agent zu unterscheiden, sondern den Grad der Agententätigkeit als ein Spektrum mit verschiedenen Ausprägungen zu betrachten. Je nach Anforderung an den Workflow kann dabei die Variante gewählt werden, die ein optimales Verhältnis von Nutzen und Unsicherheit aufweist.
Implementierung
Wie im vorherigen Abschnitt dargelegt, existieren zahlreiche Ansätze zur Realisierung agentischer Programmabläufe. Im Folgenden wird eine besonders verbreitete Technik vorgestellt: REACT [3]. In diesem Ansatz agiert das LLM in zwei aufeinanderfolgenden Phasen: REasoning (Nachdenken) und ACTing (Handeln). Das Aufteilen von Planen und Handeln führt hierbei zu signifikant besseren Ergebnissen, da das LLM erst “nachdenken” kann bevor es konkrete Schritte umsetzt.
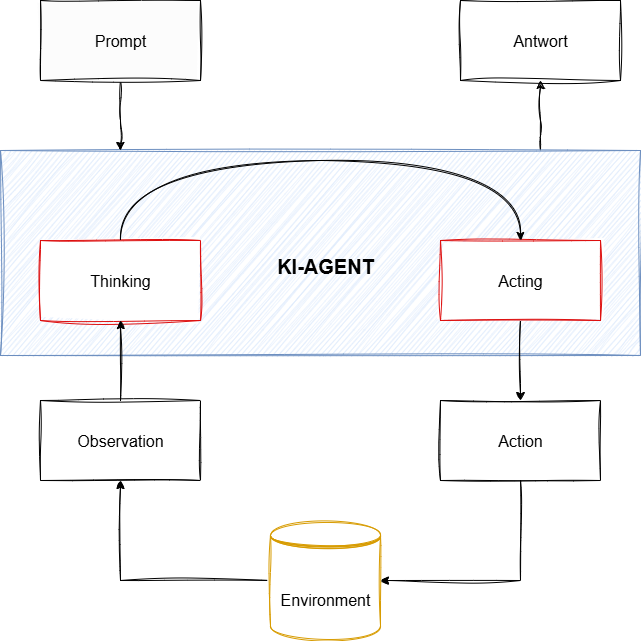
Wann lohnt sich der Einsatz?
Wie in den vorherigen Abschnitten erläutert, kann der Einsatz von agentischen LLM-Workflows die Qualität der Antworten im Vergleich zu linearen LLM-Workflows verbessern. Er birgt jedoch auch Komplikationen, wie eine erhöhte Workflow-Komplexität, einen höheren Ressourcenbedarf und längere Antwortzeiten. Dies gilt sowohl für den Einsatz von eingekauften Lösungen, wie Rovo von Atlassian, als auch für die Entwicklung eigener Agenten. Der Kompromiss zwischen Antwortqualität und diesen Problemen muss für jeden individuellen Anwendungsfall sorgfältig betrachtet und bewertet werden.
Aufbauend auf der zuvor definierten Vielfalt an Steuerungsmöglichkeiten innerhalb eines LLM-Agenten, von starren, vordefinierten Abläufen bis zu vollständig dynamischen Prozessen, müssen bei der Bewertung der Trade-offs auch diese Freiheitsgrade berücksichtigt werden. LLMs sind nicht fehlerfrei; jede getroffene Entscheidung kann unerwartet oder sogar falsch sein und zu unvorhergesehenen Abläufen im Workflow führen.
Dies führt sowohl in der Entwicklung als auch im Betrieb zu zusätzlichem Aufwand und macht das sorgfältige Testen während beider Phasen unerlässlich. Es bedingt zudem Transparenzpflichten, Monitoring- und Fallback-Mechanismen.
Zusammengefasst bedeutet dies, dass die Vorteile einer höheren Antwortqualität durch agentische LLM-Workflows stets gegen den zusätzlichen Aufwand und die potenziellen Risiken unerwarteter Abläufe abgewogen werden müssen. Insbesondere in Anwendungsfällen, in denen ein Workflow vielfältige Aufgaben mit hoher Diversität abdecken soll, wie etwa im Kundenservice, lohnt sich der Einsatz von LLM-Agenten. Während viele Systeme oftmals in festen Abläufen arbeiten und lediglich vordefinierte Antwortmuster liefern, können agentische Workflows flexibel und individuell auf komplexe Anfragen reagieren.
Vielleicht reicht eine Optimierung der 80% häufigsten Fälle aus und eine Fokussierung auf diese Fälle macht dann ein Agentensystem überflüssig? Um den optimalen Freiheitsgrad des agentischen Workflows zu bestimmen, ist in der Praxis häufig ein experimenteller Ansatz erforderlich.
Fazit
Ziel dieses Artikels ist es, einen ersten Überblick über das LLM-Agenten Thema zu geben. Neben der Verbesserung bestehender Programme, wie in den vorangegangenen Abschnitten dargestellt, eröffnen agentische LLM-Programme die Möglichkeit, Prozesse weiter zu automatisieren. Agentensysteme können dabei beliebig komplex aufgebaut werden, wie in Konstellationen, in denen mehrere Agenten zusammenarbeiten, um herausfordernde Probleme eigenständig zu lösen, die bislang für Automatismen unerreichbar waren.
Entscheidend ist immer, den optimalen Grad an eigenständigen Entscheidungsmöglichkeiten des LLMs für die jeweilige Aufgabe im Blick zu behalten. Durch fortlaufendes Monitoring, experimentelle Optimierung und ein sorgfältiges Abwägen der Trade-offs lassen sich die Potenziale agentischer LLM-Workflows nachhaltig nutzen.
Quellen
[1] J. Yang et al., “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering,” arXiv (Cornell University), May 2024, doi
[2] T. Yu, S. Zhang, and Y. Feng, “Auto-RAG: Autonomous Retrieval-Augmented Generation for Large Language Models,” arXiv (Cornell University), Nov. 2024, doi
[3] S. Yao et al., “ReAct: Synergizing Reasoning and Acting in Language Models,” arXiv (Cornell University), Mar. 09, 2023
