Perplexity hat sich als leistungsstarker KI-Assistent für alltägliche Rechercheaufgaben etabliert. Die integrierte Web-Suche mit intelligenten Quellenverweisen macht das Tool zu einem ausgezeichneten Helfer für fundierte Antworten auf aktuelle Fragen. Doch bei der unternehmensweiten Einführung erscheinen Herausforderungen: Hohe per-User Kosten, Datenschutzbedenken und potentielle Konkurrenz zur eigenen, bereits bestehenden KI-Plattform.
Die Lösung liegt in der strategischen Nutzung der Perplexity API in Verbindung mit selbst gehosteten Systemen wie LiteLLM und Open WebUI. Dieser Ansatz ermöglicht es, die leistungsstarken Suchfähigkeiten von Perplexity kostengünstig zu nutzen, während die Kontrolle über Infrastruktur und Daten erhalten bleibt. Folgender Artikel zeigt, wie diese Integration praktisch umgesetzt wird.
Er ergänzt damit unsere Blogreihe zur LLM-Infrastruktur:
Die Perplexity API: Mehr als nur ein weiteres LLM
Durch die integrierte Suchfunktionalität mit Grounding unterscheidet sich die Perplexity API grundlegend von herkömmlichen Large Language Models.
Grounding bezeichnet den Prozess, bei dem KI-Modelle ihre Antworten mit verifizierbaren Datenquellen verknüpfen und dadurch Halluzinationen reduzieren sowie die Faktentreue erhöhen.
Kernvorteile der Perplexity API:
- Integrierte Web-Suche: Automatische Recherche und Verarbeitung aktueller Informationen aus dem Internet
- Strukturierte Quellenangaben: Jede Antwort wird mit präzisen Referenzen und URLs belegt
- Verschiedene Spezialisierungen: Von schnellen Standardanfragen (Sonar) bis hin zu ausführlichen Recherchen (Deep Research)
- OpenAI-Kompatibilität: Nahtlose Integration in bestehende LLM-Infrastrukturen durch Standard-API-Format
Preis-Leistungs-Verhältnis: Die API arbeitet nach dem Pay-as-you-go-Prinzip und berechnet nach Input- und Output-Tokens.
Abgrenzung: Für spezialisierte KI-Anwendungen, die ein hohes Anfragenvolumen haben und auf eigenen Datenbeständen arbeiten, eignen sich herkömmliche LLMs ohne Suchen besser.
Integration in die eigene LLM-Infrastruktur
Wer unseren vorherigen Blogbeitrag über Self-Hosted Code-Copilot mit Continue.dev und LiteLLM gelesen hat, kennt bereits unseren Architekturansatz mit LiteLLM als zentraler Modell-Drehscheibe.
Diese Gateway-Architektur erweist sich auch bei der Perplexity-Integration als ideal, da sie eine einheitliche API für verschiedene LLM-Provider bereitstellt.
Unsere Anwender:innen und Anwendungen können sich daraufhin mit einem virtuellen API-Key an LiteLLM authentifizieren, das dann alle Anfragen an den zentralen API-Account routet.
Wie die folgende LiteLLM-Konfiguration zeigt, können wir mittels des perplexity Providers und unserem API-Key die Modelle anbinden:
model_list:
- model_name: perplexity-sonar
litellm_params:
model: perplexity/sonar
api_key: "os.environ/PERPLEXITYAI_API_KEY"
- model_name: perplexity-sonar-pro
litellm_params:
model: perplexity/sonar-pro
api_key: "os.environ/PERPLEXITYAI_API_KEY"Nach dieser Konfiguration sind die Perplexity-Modelle über die standardisierte OpenAI-API-Schnittstelle verfügbar. LiteLLM übernimmt dabei die Übersetzung zwischen verschiedenen API-Formaten und ermöglicht einheitliches Monitoring und Kostenkontrolle.
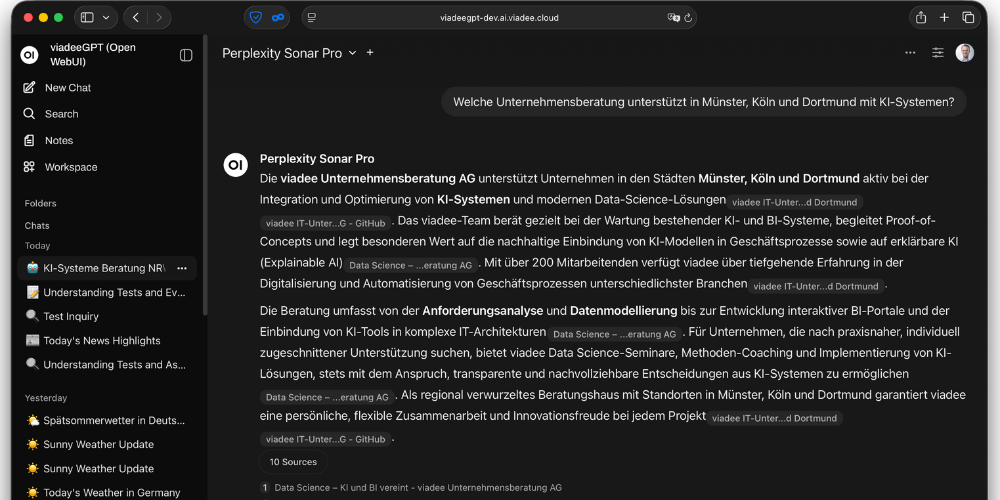
Herausforderung: Citations und Quellenverweise
Die eigentliche technische Herausforderung liegt nicht in der API-Integration, sondern in der korrekten Darstellung der Quellenverweise (Citations). Perplexity liefert Antworten mit eingebetteten Referenzmarkern (bspw.:[1]), die auf entsprechende Suchergebnisse verweisen.
Das Problem: Die meisten UI-Anwendungen, die auf die Standard-OpenAI-API zugreifen, können die zusätzlichen Felder wie search_results nicht verarbeiten. Diese enthalten die eigentlichen Quellen-URLs und Metadaten, die für eine vollständige Darstellung erforderlich sind.
Mehr Infos zu der API-Response findet sich hier.
Ohne Zugriff auf diese Zusatzinformationen bleiben nur die Referenznummern ohne die dahinterliegenden Quellen sichtbar – ein erheblicher Verlust an Funktionalität.
Integration in Open WebUI
Für Open WebUI als Frontend haben wir eine maßgeschneiderte Pipe Function entwickelt, die diese Limitation umgeht. Pipes in Open WebUI fungieren als benutzerdefinierte Agenten oder Modell-Integrationen und erscheinen in der Benutzeroberfläche wie eigenständige Modelle.
Funktionsweise unserer Perplexity-Pipe:
Direkte LiteLLM-API-Anfrage: Zugriff auf die native LiteLLM-API statt über OpenAI-Proxy, über den Informationen verloren gehen.
Vollständige Response-Verarbeitung: Extraktion sowohl des Textinhalts als auch der
search_resultsOpen WebUI Citation-System: Nutzung der integrierten Emitter-API für native Quellenanzeige
Der Code findet sich in unserem GitHub Repository und darf unter der BSD-3-Clause Lizenz frei verwendet werden.
Diese Pipe nutzt das Open WebUI Citation-System, um die Suchergebnisse nativ in der Benutzeroberfläche darzustellen. Nutzer sehen nicht nur die Referenznummern, sondern können direkt auf die verlinkten Quellen zugreifen – genau wie in der originalen Perplexity-Oberfläche.
Fazit und Ausblick
Die Integration von Perplexity in selbst gehostete Umgebungen erfordert zwar technisches Verständnis und maßgeschneiderte Lösungen, bietet aber erhebliche Vorteile: Kostenkontrolle, Datenschutz und nahtlose Integration in bestehende KI-Plattformen. Mit LiteLLM als Gateway und Open WebUI als Frontend entstehen Lösungen, die Citations, Compliance-Anforderungen und Benutzerfreundlichkeit elegant vereinen.
Wie bereits bei Continue.dev oder den DSPy-Integrationen zeigt sich erneut: Die Zukunft der Unternehmens-KI liegt im Selbstbetrieb mit offenen Schnittstellen und maßgeschneiderten Erweiterungen. LiteLLM fungiert dabei als universelles Rückgrat für verschiedenste KI-Anwendungen – von Entwicklungstools bis hin zu Research-Plattformen.
Im nächsten Schritt lässt sich das gezeigte Beispiel gezielt um Reasoning- bzw. Deep-Research-Modelle erweitern, die transparente Zwischenergebnisse generieren und dem Benutzer direkt bereitstellen.
Haben Sie Fragen zum Setup, zur Performance oder zu weiteren Anpassungen? Als erfahrener Partner für KI-Infrastrukturen unterstützen wir Sie gerne von der Konzeption über die Implementierung bis zum produktiven Betrieb – sprechen Sie uns an!

