Bildquelle: „Football Tactics Board - Strategy“ von Footy.com Images, CC BY 2.0
Legacy Software hat oftmals einen zweifelhaften Ruf. Dabei bedeutet Legacy im Wortsinne Vermächtnis oder auch ein wertvolles Erbe. “A legacy is something valuable that you have inherited” [1]. Und bei Legacy Software ist es nicht anders: das ist Software, die erfolgreich in Produktion läuft und das Geld der Unternehmen verdient. Der Umgang mit Legacy Software ist in den letzten Jahren vermehrt in den Fokus vieler Unternehmen geraten. Das liegt einerseits an den demographischen Faktoren: viele erfahrene Software-Entwickler der Babyboomer-Generation gehen in den nächsten Jahren in den wohlverdienten Ruhestand und mit ihnen auch das fachliche und technische Wissen über die Legacy Software. Auf der anderen Seite stehen viele IT-Abteilungen vor der Herausforderung, bestehende Anwendungen technologisch zu modernisieren, um z.B. die Vorteile der Cloud auszunutzen oder Benutzeroberflächen anzubieten, die heutige Anforderungen an die User Experience erfüllen.
In einer dreiteiligen Artikelserie werde ich verschiedene Aspekte der Legacy Ablösung betrachten. Im ersten Teil ging es um die Strategien auf Ebene eines Unternehmens und der gesamten Anwendungslandschaft. In diesem zweiten Teil widme ich mich konkreten Taktiken zur Modernisierung einzelner Anwendungen, bevor im dritten Teil mehrere Architekturmuster vorgestellt werden, um ein schrittweises Reengineering von Legacy-Anwendungen im laufenden Betrieb zu ermöglichen.
Den ersten Teil dieser Serie mit dem Fokus auf unternehmensweite Strategien zur Legacy-Ablösung finden Sie hier:
Scheibchenweise modernisieren
Die grundlegende Taktik der Legacy-Ablösung entspricht dem Leitsatz “Teile und herrsche”. Die zu modernisierende Anwendung wird in Teile und Komponenten aufgeteilt, die schrittweise einzeln modernisiert werden. Eine Komponente nach der anderen. Die häufigste Ausprägung dieser Taktik ist die schichtenweise Modernisierung. Wenn wir die klassische Drei-Schichten-Architektur aus Abb. 1 betrachten, dann haben die einzelnen Schichten unterschiedliche Innovationszyklen. Im Bereich der Frontends und User Interfaces haben wir in den vergangenen Jahrzehnten einen rasanten Wandel erlebt mit einem Innovationszyklus im Bereich von 3-5 Jahren für eine spezielle Technologie. Angefangen mit textbasierten User Interfaces der 70er/80er Jahre (auch bekannt als 3270-Emulation [2] nach den namensgebenden IBM-Terminals) über GUIs (graphische User Interfaces) und fensterbasierte Desktop-Benutzeroberflächen der 90er und 2000er Jahre bis hin zu Web-Anwendungen und schließlich mobilen Apps - häufig als Single-Page-Applications - in der heutigen Zeit. Dieser technologische Wandel ging auch mit stark veränderten Erwartungen der Benutzer einher und führt zu einem hohen Modernisierungsdruck in der UI-Schicht. Als Beispiel für mittlerweile nahezu ausgestorbene Frontend-Technologien lassen sich Adobe Flash oder Microsoft Silverlight anführen und die geneigte Leserin mag sich auch an ehemals marktbeherrschende Technologien wie Java Swing, Eclipse SWT oder das Google Web Toolkit erinnern, die für Nachwuchs-Entwickler:innen entweder gänzlich unbekannt oder hemmungslos veraltet sind.
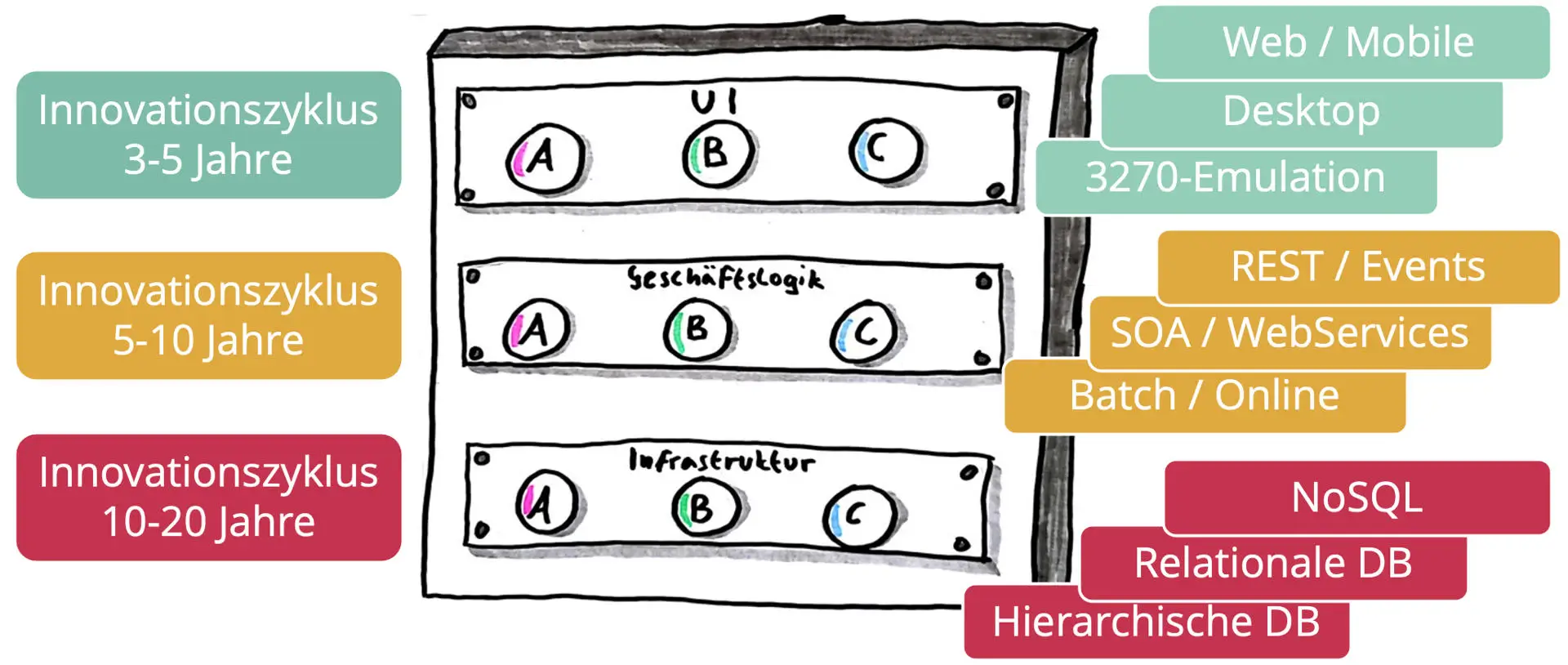
Wenn die Schichtentrennung zwischen UI und Geschäftslogik vernünftig implementiert wurde, ist es möglich, die Frontend-Technologie mit vertretbarem Aufwand auszutauschen und dieselbe Geschäftslogik in einem zeitgemäßen und ansprechenden Design für die Benutzer:innen zu präsentieren. Dabei darf man nicht vergessen, dass nicht nur das Aussehen (im Sinne UI), sondern auch die Benutzerführung und das Benutzererlebnis (neudeutsch User Experience), regelmäßig aktualisiert und auf den Stand der Technik gebracht werden müssen. Der Modernisierungsdruck entsteht dabei nicht für alle Nutzergruppen gleich stark. Während Anwendungen für Endkund:innen deutlichen höheren Ansprüchen für UI/UX ausgesetzt sind, kann eine zehn Jahre alte Desktopanwendung für die Sachbearbeitung im Innendienst durchaus noch die Anforderungen erfüllen insb. in Bezug auf die Effizienz und Bearbeitungsgeschwindigkeit.
Die Zeitkapselung
Betrachtet man die historisch gewachsenen IT-Systeme und Anwendungslandschaften in größeren Unternehmen, fühlt man sich hin und wieder wie auf einer Zeitreise. Ein besonders illustratives Beispiel ist eine Überweisung im Online-Banking (Abb. 2). Die meisten von uns machen das in einer Banking-App auf dem Smartphone, mit einer ansprechenden UI/UX. Die Apps werden laufend aktualisiert, sodass Anwender:innen gar keine Versionssprünge mehr wahrnehmen. Beim Bestätigen der Überweisung geht dann die Zeitreise durch die IT-Historie los. Die App kommuniziert mit Services eines REST-Backends, die im Laufe der 2010er-Jahre implementiert wurden und deren Fachlichkeit sich seitdem nur marginal geändert hat. Der nächste Technologiesprung hin zu Echtzeitüberweisungen steht zwar vor der Tür, ist aber aktuell noch ein sehr seltener Ausnahmefall. Der Service “Geld überweisen” ist seit der SEPA-Einführung für einheitliche Überweisungen im Euro-Zahlungsverkehrsraum auf der Basis einer IBAN im Jahr 2014 im Wesentlichen unverändert geblieben.
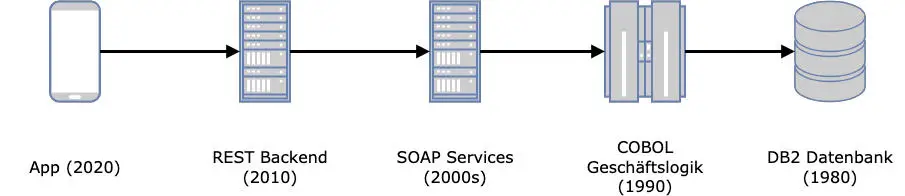
Wahrscheinlich dient der REST-Service aber nur als Durchlauferhitzer mit ein paar fachlichen Validierungen und leitet die Daten an den eigentlichen Geschäftsprozess weiter, der im Laufe der 2000er-Jahre als SOAP-Web-Service bereitgestellt wurde. Damals war die serviceorientierte Architektur (SOA) der Stand der Technik, auf den nahezu alle Unternehmen aufgesprungen sind. Der fachliche Kern der Überweisung ist in dieser Schicht implementiert und stammt damit noch aus der Zeit vor der SEPA-Einführung und wurde 2014 grundlegend umgestellt, um z.B. den Wechsel von Bankleitzahl und Kontonummer auf IBAN (und ggf. BIC) der SEPA-Einführung zu implementieren. In dieser Schicht werden vielleicht das zu belastende Konto und die Empfängerbank ermittelt sowie Überweisungslimits geprüft.
Mit diesen Informationen werden dann in aller Regel COBOL-Module aus den 1990er-Jahren (oder früher) aufgerufen, die eine Soll-Buchung auf dem zu belastenden Konto durchführen, den Buchungstag oder Überziehungszinsen ermitteln. Hier liegt die tatsächliche bankfachliche Logik versteckt, die in den frühen Phasen der Digitalisierung von hand- oder maschinengeschriebenen Papierakten in erste Computer überführt wurde. Manchen mag der Begriff Sparbuch noch geläufig sein und mein erstes Sparbuch als Kind war tatsächlich ein Sparbuch als kleines DIN-A6-Heft, in dem bei jedem Weltspartag die wenigen gesparten D-Mark im ursprünglichen Wortsinne verbucht wurden. Der Schalterbeamte schrieb eine neue Zeile per Hand oder Schreibmaschine mit dem Buchungsbetrag und dem neuen Kontostand in das Buch hinein. Und dieses Sparbuch war meine Kopie der Datenbank - oder zumindest des Ausschnitts mit meinem Konto.
Die Datenbestände für einzelne Sparbücher bzw. Sparkonten, Girokonten und alle weiteren Daten lagen und liegen seit dieser ersten Phase der Digitalisierung in einer Mainframe-Datenbank auf einem Großrechner, in den meisten Fällen in einer IBM DB2-Datenbank. Die ersten Datenstrukturen wurden vielleicht schon in den 1980er-Jahren kurz nach der Erfindung relationaler Datenbanken angelegt oder sonst zeitgleich mit den COBOL-Programmen. COBOL ist eine nicht mehr zeitgemäße prozedurale Programmiersprache ohne Unterstützung für funktionale Programmierung oder Objektorientierung. Es gibt zwar eine objektorientierte Erweiterung für den COBOL-Standard, aber mir ist in den letzten 15 Jahren, seitdem ich mich mit Legacy-Software und COBOL beschäftige, noch kein produktives Programm zu Augen gekommen, das objektorientierte Features benutzt. Aber auf dem IBM-Mainframe konnte (und kann) man in der Kombination von COBOL und DB2 sehr effizient Datenverarbeitungsprogramme schreiben, die gemäß dem EVA-Prinzip (Eingabe-Verarbeiten-Ausgabe) Daten aus der Datenbank lesen (z.B. den aktuellen Kontostand), diese mit aktuellen Eingaben (z.B. dem Überweisungsbetrag) verarbeiten und das Ergebnis (z.B. den neuen Kontostand) wieder in die Datenbank schreiben. Das liegt vor allem an dem Feature des sog. Embedded SQL, d.h. des eingebetteten SQL-Statements, das direkt in COBOL-Programme hinein programmiert werden kann. Das ist annähernd vergleichbar zu JDBC-Statements in Java-Programmen, nur dass vollständiges SQL mit allen Features der Datenbank genutzt werden kann und es einen sog. DB2-Preprozessor gibt, der die SQL-Statements in Datenzugriffe auf der DB2-Datenbank übersetzt und dabei syntaktisch (SQL-Syntax) und sogar semantisch (Feldnamen und Datentypen) überprüft. Man erhält also die ganze Mächtigkeit von SQL kombiniert mit allen Vorteilen einer kompilierten Programmiersprache, sodass schon zur Compilezeit sichergestellt ist, dass der Datenbankzugriff ausführbar ist.
Zurück zu meiner Überweisung vom Smartphone: Diese ist jetzt von einer Schicht zur nächsten jeweils in einer Zeitkapselung in die technologische Vergangenheit gereist und schließlich ausgeführt worden. Diese Zeitkapselung ist die grandiose Anwendung einer erfolgreichen Taktik: Kapselung. Der Begriff ist im Rahmen der Objektorientierung sehr prominent geworden um interne Daten einer Klasse vor dem Zugriff von außen zu schützen. Kapselung ist ein sehr wichtiges Prinzip, um die Schnittstelle einer Funktion von der Implementierung zu separieren und ermöglicht das Refactoring der Implementierung, ohne die Schnittstelle und deren Verwender anzupassen. Und dieses Prinzip gab es tatsächlich schon vor der Objektorientierung, erstmals beschrieben von David Parnas 1972 für Module [3]. Es wurde in der gerade beschriebenen Zeitreise mehrfach erfolgreich angewandt, um bestehende Geschäftslogik früherer Jahrzehnte für neue Zugangskanäle und Anwender:innen verfügbar zu machen. Ursprünglich durfte nur der Schalterbeamte eine Überweisung im System erfassen und Kund:innen durften nur ihre Überweisungsanforderung auf Papier eintragen. Dieses Prinzip ist in den Schichten der Architektur ähnlich wie bei Jahresringen immer noch erkennbar, nur dass Kund:innen heute ihre Überweisungsanforderung in einer App erfassen und es nicht mehr ins System abgetippt, sondern über Schnittstellen übertragen wird.
Kapselung ist eine zentrale Taktik nicht nur für Legacy-Migrationen. Die Kapselung sorgt einerseits für eine fachliche Wiederverwendung der Geschäftslogik und dient andererseits dem Investitionsschutz für bereits geschriebene Programme, die nicht bei jedem Technologiewechsel in den gerade aktuellen Programmiersprachen neu entwickelt werden müssen. Mittlerweile stößt diese Taktik aber an ihre Grenzen, da wir den ersten großen demographischen Wandel in der IT-Industrie erleben und viele Know-How-Träger:innen in den wohlverdienten Ruhestand wechseln. Die Technologien wie COBOL, in denen die bankfachliche Logik implementiert ist, werden zunehmend weniger beherrscht und damit werden Anpassungen aufwändiger und teurer, sodass ein Reengineering auf moderne Technologien sich finanziell rechnet. Und in manchen Fällen ist das Reengineering sogar zwingend, weil bestehende Funktionalität mangels Know-How nicht mehr gewartet werden kann und dadurch untragbare Risiken für das Business entstehen.
Migrate the data - toss the code
Die Daten migrieren und den Code “werfen, schleudern schütteln” ist ein zentraler Leitsatz aus einem frühen Referenzwerk für Legacy-Migrationen [4]. Dahinter steht die Überzeugung, dass die Daten eines Unternehmens der eigentliche Wert sind: Die Daten sind geschäftskritisch und können nicht ersetzt werden. Der Code hingegen ist nicht kritisch und soll ja gerade durch die Migration ersetzt werden. Die Formulierung ist sicherlich etwas überspitzt, weil die Daten durch den Code erzeugt und verändert werden und viel kritische Geschäftslogik im Code abgebildet ist. Aber der Datenschatz der Anwendung hat für jede Legacy-Migration einen sehr hohen Stellenwert.
In vielen Migrationsprojekten ist aber die Fragen nach dem Datenmodell wichtiger als die Daten selbst: Soll das logische und physische Datenmodell im Rahmen der Migration überarbeitet werden? Bezieht sich das Reenginering nur auf den Code oder auch auf die Datenstrukturen in der Datenbank? Meine taktische Empfehlung aus den Erfahrungen vieler Migrationsprojekte ist: Lasst das Datenmodell für die Reengineering-Phase weitestgehend stabil! Diese generische Empfehlung leitet sich aus zwei Argumenten ab.
Zum einen sind Datenmodelle von Legacy-Anwendungen oft mit viel Gehirnschmalz und Aufwand gut designed worden. Anwendungen mit schlechten oder ungeeigneten Datenmodellen hätten gar nicht lange genug überlegt, um in den Status einer seit Jahren erfolgreich produktiven Legacy-Anwendung zu kommen. Auch wenn der Impuls entsteht, das Datenmodell aufzuräumen, zu entrümpeln und alte Zöpfe abzuschneiden, muss man bei einer detaillierten Betrachtung oft erkennen, dass die Merkwürdigkeiten des Datenmodells den fachlichen Anforderungen geschuldet sind. Der Wunsch nach einer Vereinfachung des Datenmodells kollidiert mit der inhärenten Komplexität der fachlichen Prozesse. Diese generische Empfehlung muss natürlich in jedem konkreten Migrationsprojekt gründlich überprüft werden und eine kritische Analyse des Datenmodells und möglicher Optimierungen sollte in jedem Migrationsprojekt durchgeführt werden. Selbst wenn daraus der Entschluss reift, das Datenmodell 1:1 zu übernehmen, wird die kritische Datenmodell-Analyse ein tiefergehendes Verständnis der Legacy-Anwendung und ihrer Fachlichkeit für das Projektteam erreichen, die für das Reengineering nützlich ist.
Zweitens sind Datenmodelle von Legacy-Anwendungen in den meisten Fällen tragfähig für das Reengineering, weil der Skill der Datenmodellierung früher sehr viel wichtiger war. Zum Zeitpunkt der Entstehung der Legacy-Anwendung war ein gutes Datenmodell mit wenig Redundanz und geringem Speicherverbrauch essenziell für den Erfolg der Anwendung. Auch die Organisation der Daten für einen effizienten Zugriff in Online-Prozessen und Batch-Prozessen spielte vor zehn oder 20 Jahren noch eine deutlich größere Rolle als heutzutage, wo Speicherplatz und Rechenleistung keinen Engpass mehr darstellen. Seit dem Siegeszug des relationalen Datenbankmodells ab den 1980er Jahren gehörte Grundlagenwissen über die relationale Algebra und Normalformen in der Datenmodellierung zum Basiswissen und Handwerkszeug jeder:s Software-Entwickler:in. In den letzten zwei Jahrzehnten hat die Bedeutung dieses Wissens und Grundkenntnisse der SQL-Sprache (Structured Query Language) zum Datenbankzugriff sukzessive abgenommen. In vielen Programmiersprachen gibt es ausgereifte Frameworks für die Datenzugriffsschicht wie z.B. Spring Data oder Hibernate im Java-Umfeld. Diese Frameworks abstrahieren von der Datenbank und übernehmen das Mapping der objektorientierten Software in relationale Datenmodelle. Der große Vorteil, dass Entwickler:innen auch ohne tiefgreifendes Verständnis von Datenbanken und der relationalen Algrebra effizient Software schreiben können, die unter der Haube auf einer relationalen Datenbank basiert, hat leider den nachteiligen Effekt, dass diese Skills nicht mehr aufgebaut werden.
Zum dritten ist es empfehlenswert, die Code-Migration und eine Datenmodell-Migration voneinander zu trennen. Das hat vor allem praktische Gründe in der Beherrschbarkeit des Migrationsvorhabens. Die Stabilität des Datenmodells hat für eine Code-Migration erhebliche Vorteile:
Vergleichstest der Legacy-Software und der neuen Software auf denselben Datenbeständen sind möglich. In vielen Migrationsprojekten sind diese Vergleichstest ein essenzieller Bestandteil zur Sicherstellung der Qualität, da automatisierte Tests für die Legacy-Software oft nicht vorhanden sind.
Schnittstellen zu Drittsystemen sind bei Legacy-Software in vielen Fällen eng an das Datenmodell gekoppelt und unzureichend fachlich abstrahiert. Die Stabilität der Schnittstellen reduziert die Komplexität des iterativen Reengineerings und ermöglicht ebenfalls Vergleichstest an den Schnittstellen und die Wiederverwendung bestehender Integrationstests.
Veränderungen des Datenmodells haben oft weitreichende Auswirkungen an vielen Stellen der Software und sind nur in Ausnahmefällen lokal begrenzt und damit gut geeignet für ein iteratives Reengineering.
All diese Gründe sprechen dafür, das bestehende Datenmodell nicht leichtfertig über Bord zu schmeißen, sondern eine kritische Analyse durchzuführen, ob das Datenmodell für zukünftige Anforderungen tragfähig ist. Sie sprechen auch dafür, bei Refactorings des Datenmodells eher lokale Optimierungen durchzuführen, als zentrale Entitäten komplett neu zu designen. Nichtsdestotrotz gibt es aber natürlich auch Migrationsprojekte, die massive Auswirkungen auf das Datenmodell haben, wenn z.B. Querschnittsfunktionen aus der Legacy-Anwendung herausgelöst und in eine Standard-Software migriert werden.
Erfolgsfaktor Brückentechnologien
Ein großer Erfolgsfaktor für das schrittweise Reengineering einer Legacy-Anwendung sind Brückentechnologien. Diese schaffen eine Verbindung von der Legacy-Welt in die neue Welt oder umgekehrt. Auch wenn die Einführung einer Brückentechnologie oder die Implementierung einer Brückenlösung als Übergangslösung mit zusätzlichen Aufwänden verbunden ist, ist dieser Aufwand gegenüber den Kosten und Risiken einer Big-Bang-Migration zu vernachlässigen. Brückentechnologien können Zugriffstechnologien auf Legacy-Infrastruktur sein, z.B. Verbindungstechnologien zum IBM-Mainframe wie z/OS Connect for CICS oder IMS Connect, die den Zugriff auf bestehende Geschäftslogik in den Legacy-Transaktionsmonitoren IMS und CICS auf dem Mainframe ermöglichen. Diese Brückentechnologien lassen sich sehr gut mit der Zeitkapselung-Taktik kombinieren. Idealerweise dient die Kapsel auch als funktionaler Adapter und stellt die Geschäftslogik entsprechend den Anforderungen der neuen Welt bereit: mit einem Anti-Corruption Layer, das in Teil drei ausführlich als Muster beschrieben wird.
Brückentechnologien machen es möglich, die Legacy-Komponenten und bereits modernisierte Komponenten fachlich und technisch zu einer Gesamtlösung zu integrieren. Damit kann die Funktionalität schrittweise reengineered werden. Ein Praxisbeispiel für diese Integration stammt aus dem Umfeld von Batch-Modernisierungen. In vielen Banken und Versicherungen gibt es eine umfangreiche Batch-Verarbeitung, also Massendatenverarbeitung, die üblicherweise nachts ausgeführt wird und z.B. im Zahlungsverkehr alle Buchungen des Tages gesammelt an den Zahlungsdienstleister übergibt oder regelmäßige Aufgaben wie Meldeverfahren an Behörden durchführt. Diese Batche stellen einzelne, gut gekapselte Funktionalitäten bereit, haben aber Abhängigkeiten untereinander in einem komplizierten Netz aus Vorgänger/Nachfolger-Beziehungen. Die Steuerung der Batch-Jobs mit Rücksicht auf die Abhängigkeiten übernimmt eine Scheduler- oder Workload-Automation-Software wie IBM Z Workload Scheduler, Stonebranch Universal Controller oder Broadcom Automic Automation. Sollen nun einzelne Batche schrittweise vom Mainframe auf eine verteilte Plattform, z.B. in Java mit dem Spring-Batch-Framework, verlagert werden, muss der Scheduler eine übergreifende Steuerung über verschiedene Betriebsplattformen ermöglichen. Der Scheduler wirkt damit entweder selbst als Brückentechnologie oder wird durch Brückenlösungen befähigt, Batch-Jobs auf verschiedenen Plattformen integriert zu steuern.
Brückenlösungen müssen nicht ein explizites Software-Produkt sein, das verschiedene Betriebsplattformen verbindet. Es kann sich auch um Architekturkomponenten handeln, die explizit für die Übergangsphase während einer Modernisierung implementiert werden. Diese auch als Transitional Architecture [5] bezeichnete Vorgehensweise ist ein bewusster Wegwerfaufwand, um das Zusammenspiel zwischen Legacy-Software und neuer Welt zu ermöglichen.
Evolutionäre Migration durch evolutionäre Architektur
Die Idee der evolutionären Architektur entspricht einer konstanten Weiterentwicklung der Architektur - im Gegensatz zu einer Architektur, die vor fünf, zehn oder 20 Jahren festgelegt und seitdem nicht geändert wurde. Die Idee ist völlig offensichtlich, so revolutionär es dem einen oder der anderen auch erscheinen mag. Eine evolutionäre Migration von Fachlichkeit und von Technologien hat immense Vorteile, da sie inhärent inkrementell und in finanzierbaren Schritten stattfindet. Der Change für Anwender:innen und Projektteams wird verkraftbarer durch die Aufteilung in viele kleine Schritte im Gegensatz zu einer großen Umstellung mit immensen Schulungsaufwänden.
Das Konzept einer evolutionären Architektur ist ausführlich in [6] beschrieben, lässt sich aber in einem Satz definieren: “Eine evolutionäre Architektur unterstützt gesteuerte, inkrementelle Veränderung über mehrere Dimensionen”. Es besteht aus drei Grundideen
Inkrementelle Veränderung: Die Architektur muss inkrementelle Veränderungen sowohl in der Software-Entwicklung als auch beim Deployment unterstützen. Dazu müssen die Funktionen modular aufgebaut und lose gekoppelt sein. Für die Deployment-Ebene kann das z.B. auch erreicht werden, in dem Services oder Komponenten versioniert werden und damit neue Versionen deployed werden können, die in schrittweise von den Verwender:innen adaptiert werden können.
Gesteuerte Veränderung durch Fitness Functions: Fitness Functions sind als Metapher aus der biologischen Evolution abgeleitet und messen die Fitness der Architektur im Hinblick auf die Erfüllung der Qualitätsanforderungen. Qualitätsanforderungen wie Sicherheit, Wartbarkeit, Performance und Verfügbarkeit sind architekturbestimmend und sollten bei jeder Veränderung weiter gewährleistet sein oder sich messbar verbessern.
Mehrere architektonische Dimensionen: Veränderungen der Architektur finden in mehreren Dimensionen statt, z.B. auf technologischer Ebene der Programmiersprachen und Frameworks und auf Datenebene der Datenmodelle und Datenbanken. Insbesondere die beiden Dimensionen der Fachdomäne (fachliche Anforderungen und Features) sowie der technischen Implementierung müssen dabei für Veränderungen in Einklang gebracht werden.
Für Migrationsprojekte liefert die Metapher der Fitness Functions großen Mehrwert bei der Planung von Tests. Eine Migration bedeutet auch eine Änderung der Systemarchitektur und hat damit großen Einfluss auf die Qualitätsanforderungen, insb. auf die Performance. In der Praxis sind automatisierte Performance-Messungen vor und nach der Migration unerlässlich, damit Faktoren wie die Laufzeit einzelner Transaktionen oder von Batch-Massenverarbeitungen oder die Antwortzeiten für Endanwender:innen kontiniuierlich überprüft werden können.
Das Konzept ist noch aus einem anderen Gesichtspunkt im Kontext Legacy-Software nützlich. Legacy-Anwendungen basieren üblicherweise auf einer Architektur, die vor vielen Jahren festgelegt und seitdem in ihren Grundprinzipien und wesentlichen Technologien unverändert geblieben ist. Eine konsequent angewandte evolutionäre Architektur bedeutet aber eine ständige, inkrementelle Veränderung dieser Prinzipien und Technologien. Alle Architekt:innen, die verhindern wollen, dass ihre Software in einigen Jahren als Legacy eingestuft und zur Migration freigegeben wird, sollten deshalb mit dem Konzept der evolutionären Architektur sicherstellen, dass eine konstante Weiterentwicklung der Architektur stattfindet.
Strategie und Taktik bilden den Rahmen für Muster zur Umsetzung
In den ersten beiden Teilen dieser Artikel-Serie zur Legacy-Ablösung wurden Strategien und Taktiken vorgestellt, die den Rahmen für Legacy-Migrationen festlegen. Im dritten Teil werden konkrete Architekturmuster zur Umsetzung einer Legacy-Ablösung vorgestellt, darunter das bekannte Strangler Fig Pattern inklusive eines Praxisbeispiels.
Dieser Blogpost wurde zuerst als Artikel im Java Magazin 9/2025 veröffentlicht: https://app.entwickler.de/xhuWRuKe1Ub
Links und Literatur
[1] Serge Demeyer, Stéphane Ducasse, Oscar Nierstrasz: Object-Oriented Reengineering Patterns
[2] IBM 3270
[3] David Parnas: On the criteria to be used in decomposing systems into modules, Communications of the ACM, Volume 15, Issue 12, 1972.
[4] Michael L. Brodie, Michael Stonebraker: Migrating Legacy Systems, Morgan Kaufmann, San Francisco 1995.
[5] Ian Cartwright, Rob Horn, and James Lewis: Transitional Architecture
[6] Neal Ford, Rebecca Parsons, and Patrick Kua: Building Evolutionary Architectures: Support Constant Change, O’Reilly, 2017.