
Prozessmodelle entwickeln dann einen strategischen Wert, wenn sie nach dem Modellieren nicht nur in der Schublade liegen, sondern genutzt, betrachtet und vor allem gefunden werden. Was sich in zahlreichen unserer BPM-Projekte bestätigt, wird mit dem Aufkommen von unternehmenseigenen RAG-Lösungen und KI-Implementierungen immer relevanter, wenn eigene Textdaten für LLMs durch intelligente Suche verfügbar werden. Wenn Texte so einfach und gut durchsuchbar werden, wer schaut dann noch gerne umständlich in verschachtelte Prozessrepositorien mit Suchfunktionen, die vielleicht nur stichwortbasiert arbeiten oder auf Ebene der Dateinamen bzw. Prozessbezeichnungen enden?
Wie man die Informationen aus BPMN-Modellen möglichst gut in ein RAG-System bekommt, hat unser Masterstudent Lukas Laakmann in seiner Thesis betrachtet. Dafür hat er einen Prototyp auf Basis unserer eigenen Prozesse und des BPMN Modeler for Confluence entwickelt, der zeigt, dass dieser Ansatz mehr leisten kann, als „nur” einfache Fragen zu beantworten.
Prozesswissen leichtgewichtig verfügbar machen
Seit 2023 beschäftigen wir uns als viadee mit Themen an der Schnittstelle von LLMs und BPM, u. a. im BMBF-Projekt Change.WorkAROUND. In spannenden Projekten konnten wir bereits lernen, dass LLMs zum Beispiel Inkonsistenzen zwischen verschiedenen Prozessdokumenten identifizieren können. Während sich in der Forschung aktuell viel darum dreht, einzelne Prozessmodelle zu generieren oder in natürlicher Sprache beschreiben zu lassen, ist eher wenig zur LLM-basierten Suche nach Prozessen und Prozess-Schritten in großen Repositorien zu finden.
Die Frage „Wie geht es weiter?” im Prozess stellt sich oft. Gerade, wenn andere (Text-) Daten wie das eigene Confluence bereits in unternehmensweite RAG-Systeme oder Rovo eingebunden sind, ist es naheliegend, auch Prozessmodelle mit durchsuchen zu wollen. Ohne spezifische Vorarbeiten, ist aber Frust zu erwarten: Unvollständige oder unpräzise Antworten, ein falsches „Dazu liegen keine Informationen vor” oder Halluzinationen sind zu erwarten, denn Prozessmodelle sind zunächst einmal nicht zugänglich für Standard-Suchwerkzeuge.
Das Ziel: Ein gut funktionierendes RAG-System macht Prozesswissen auch für Personen ohne BPMN-Kenntnisse einfach zugänglich: mit konkreten Antworten auf ihre Fragen in natürlicher Sprache – auf Basis von BPMN, aber ohne die Notwendigkeit, BPMN im Detail „verstehen” zu müssen. Das unterstützt den partizipativen Ansatz im Prozessmanagement, den viadee seit Jahren mit dem BPMN Modeler erfolgreich verfolgt.
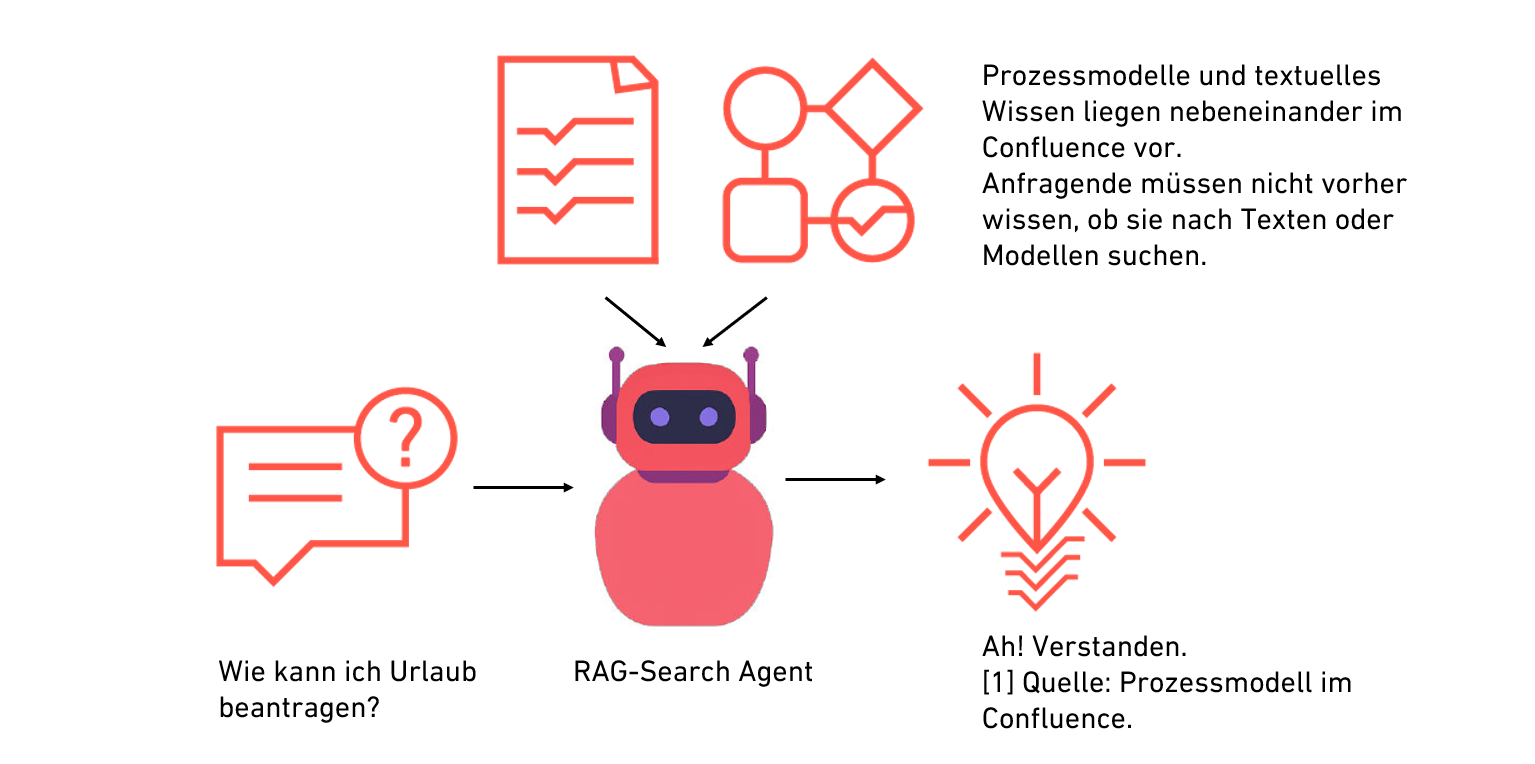
Eine Frage mit Prozessbezug wird im Chat gestellt. Daraufhin beginnt eine „intelligente” ähnlichkeitsbasierte Suche über die eigenen Prozessmodelle. Dem LLM werden abschließend die Top-Resultate bereitgestellt, um daraus eine natürlichsprachliche Antwort zu generieren, wobei die Quellenliste zur Absicherung und Kontrolle ebenfalls ausgegeben wird.
Damit ein solches Tool zur wertvollen Unterstützung wird, sollten die Antworten natürlich korrekt und zuverlässig sein. Jedenfalls muss eine Nachvollziehbarkeit durch Quellenangaben gerade in kritischen Geschäftsanwendungen sichergestellt sein und die Informationen durch Integration in das produktive Prozessrepositorium immer aktuell sein.
Sichere, offene und performante technische Umsetzung
Und natürlich muss der Datenschutz nicht nur aus regulatorischen Gründen gesichert sein. Schließlich vertrauen wir als Unternehmen dem LLM sensible Prozessinformationen und als Mitarbeitende unseren Konversationsverlauf an: Wir gestehen durch die Anfrage Unsicherheit zum Soll-Prozess ein. Daher verwendet unser Prototyp LLMs von Azure OpenAI mit Hosting in der EU unter geprüften und freigegebenen Bedingungen.
Unser bewährter Open-Source-Tech-Stack aus Open WebUI als User-Interface und LiteLLM als Middleware ermöglicht es aber auch, andere Modelle – auch lokal – zu nutzen. Während RAG für Textdaten inzwischen immer öfter gut „von der Stange” in Open WebUI funktioniert, ist die Retrieval-Performance über das XML der Prozessmodelle ausbaufähig – schließlich sind es keine herkömmlichen Texte, auf die Embedding-Modelle für die Suche trainiert sind. Die in XML kodierten Prozessmodelle sind in 2D dargestellte Graphen, der Blick eines LLM oder Embeddingmodells darauf ist aber ein eindimensionaler Text.
Daher war die Retrieval-Optimierung mit LangChain ein ganz wesentlicher Bestandteil des Projekts - geprüft mit einem eigenen, realitätsnahen Testdatensatz aus Fragen und relevanten Antworten zu viadee-Prozessen, z. B. „Was passiert, nachdem eine Bewerbung bei der viadee eingegangen ist?” oder „Wer ist bei Elternzeitanträgen beteiligt?”.
Ergebnis: Kleine Veränderungen wie Chunking oder eine Transformation in JSON reißen nicht viel. Andere regelbasierte Transformationen sind oft schwierig, weil BPMN-Konzepte wie Lanes oder Annotationen nicht geeignet dargestellt werden können. Deutlich besser funktioniert die Suche, wenn die Prozessmodelle zuvor einmalig von einem LLM in eine kompakte natürlichsprachliche Form gebracht werden. Mit diesen Zusammenfassungen konnten wir sehr gute Retrievalergebnisse mit einem MRR (Mittlerer Reziproker Rang) von über 0,8 auf einer Datenbasis mit über 700 BPMN-Modellen erzielen.
Durch die LLM-Zusammenfassungen können aber Details verloren gehen. Daher haben wir unser RAG-System mithilfe von LangGraph agentisch realisiert, damit es einerseits für die Suche die Zusammenfassungen nutzen kann, für die Antwortgenerierung aber die vollständigen Informationen aus dem Originalmodell in XML berücksichtigt werden können, sobald klar ist, in welchem BPMN-Modell sich die Antwort versteckt.
Mehrwerte: vielfältige Anwendungen, Entlastungen und Zugänglichkeit
Kreative Testerinnen und Tester bei der viadee hatten direkt viele Ideen zur Nutzung des Systems über einfache Verständnisfragen hinaus, etwa zur Zusammenfassung von Prozessen oder zur Generierung von Verbesserungsvorschlägen. Um diese Anwendungsfälle bestmöglich zu unterstützen, wurden Prompt-Vorschläge integriert. Und dank guter Integration mit der Wissensbasis sind immer Links und Metadaten vorhanden, sodass man nicht bei der LLM-Antwort stehen bleibt, sondern sie als Einstiegspunkt für die eigene Arbeit oder weitergehende Recherche nutzen kann.
In diesen Anwendungsfällen konnten wir gute Ergebnisse erzielen:
Verständnisfragen: der RAG-Klassiker, die berühmte “Suche nach der Nadel im Heuhaufen” - “Was ist der nächste Schritt, nachdem…?” oder “Wer ist im Prozess xy zuständig für …?”.
Zusammenfassung und Abstraktion: einen Überblick über einen Prozess bekommen, ohne das Originalmodell in der Tiefe betrachten zu müssen, und dabei die relevanten Informationen in andere Darstellungen wie z. B. RACI-Matrizen überführen.
Analyse und Verbesserungsvorschläge: die Kreativität und das Weltwissen von LLMs nutzen, um die eigenen Prozessmodelle und Prozesse zu verbessern. Auf Prompts wie “Was sind die größten Schwachstellen des Prozesses xy?” können LLMs überraschend hilfreiche Einblicke generieren. Im begrenzten Maß eignet sich der Ansatz auch, um z. B. zwei Prozessmodelle zu vergleichen.
Feedback von verschiedenen Nutzergruppen hierzu zeigt:
Die generierten kompakten und verständlichen natürlichsprachliche Erklärungen sind insbesondere für Mitarbeitende mit wenig BPMN-Kenntnissen eine Vereinfachung.
Durch automatisierte Beantwortung wiederkehrender prozessualer Fragen können operative Mitarbeitende entlastet werden.
Gerade für neue Mitarbeitende mit hohem Informationsbedarf hinsichtlich (interner) Prozesse bietet der Chatbot einen einfachen und niedrigschwelligen Einstieg.
Erläuternde Texte im Sinne von „Übersetzungen” von BPMN-Modellen in natürliche Sprache müssen nicht mehr von Hand geschrieben werden, um das Wissen allgemeinverständlich verfügbar zu machen - der Chatbot ist eine Dokumentationshilfe.
Limitierungen im Prototyp: LLM-Fähigkeiten, Ähnlichkeitssuche und Datenqualität
Natürlich arbeitet der Prototyp nicht perfekt. Typische Schwächen von LLMs konnten unsere Testpersonen auch hier beobachten. Etwa der Impuls, zu ausführlich oder ausweichend zu antworten, oder Schwierigkeiten beim Zählen von BPMN-Elementen. Entsprechende AI-Literacy für Anwendende ist wichtig, um unrealistischen Erwartungen vorzubeugen!
RAG bleibt RAG: eine ähnlichkeitsbasierte Suche, bei der die besten Ergebnisse (üblicherweise eine einstellige Anzahl) dem LLM zur Verfügung gestellt werden. Anfragen, die versuchen, zu aggregieren („Nenne mir alle Prozesse, in denen System xy eingesetzt wird.”) können prinzipiell nicht beantwortet werden - hierfür sind spezifische Suchmechanismen aus dem Process Querying wie Process Query Languages oder Ähnlichkeitssuchen, die auf Graphstrukturen beruhen, erforderlich. LLMs könnten dabei auch unterstützen und entsprechende Anfragen formulieren.
Und wie bei allen Data-Science-Projekten muss ein Blick auf die Datenzusammensetzung und -qualität geworfen werden: Habe ich eine globale Prozesswissensbasis oder kuratierte, themenspezifische Datensätze? Je nach Anwendungsfall ist das entscheidend, denn „gefunden wird, was da ist”. Habe ich zehn mögliche Varianten desselben Prozesses unüberlegt zu meiner Datenbasis hinzugefügt, habe ich keine Garantie, dass mein RAG-System immer die aktuellste oder tatsächlich erwünschte Version findet.
In der Realität habe ich zu einem Zeitpunkt nicht nur Fragen, die Prozessmodelle betreffen, sondern denke themenspezifisch. Hier gibt es dann auch Wissen aus Textdaten, das einbezogen werden sollte, um mich in dieser Situation zu unterstützen. Das spricht für einen Ansatz wie den BPMN Modeler, wo ich umgebendes Wissen aus einem Wiki dann auch in die LLM-Antwort einfließen lassen kann.
Ausblick: tiefere Integration und Weiterentwicklung
Insgesamt hat uns der Prototyp gezeigt, dass eine intelligente Suche über BPMN-Modelle mit RAG ein lohnenswerter Ansatz ist und die interdisziplinäre Zusammenarbeit auf Basis von Prozessmodellen verbessern kann.
Nachdem der Prototyp Anwendbarkeit und Nutzen dargestellt hat, denken wir nun darüber nach, wie wir den Ansatz bestmöglich weiterentwickeln. Gerade mit Atlassian Rovo, das auch vor Kurzem in unser Confluence eingezogen ist, bieten sich neue Möglichkeiten, den Chat mit den Prozessmodellen direkt in Confluence zu integrieren, wenn es dafür eine Nachfrage gibt.
Haben Sie einen Anwendungsfall, in dem Sie selbst Ihre Prozessmodelle intelligent durchsuchen und anschließend mit ihnen chatten möchten? Was ist Ihnen dabei wichtig?
Der Inhalt dieses Artikels basiert auf der Masterarbeit “Mit Retrieval-Augmented Generation von BPMN zu Chatbots“ von unserem Masterstudenten Lukas Laakmann.

