
Bildquelle: „Pattern“ von oatsy40, CC BY 2.0
Legacy Software hat oftmals einen zweifelhaften Ruf. Dabei bedeutet Legacy im Wortsinne Vermächtnis oder auch ein wertvolles Erbe. “A legacy is something valuable that you have inherited” [1]. Und bei Legacy Software ist es nicht anders: Das ist Software, die erfolgreich in Produktion läuft und das Geld der Unternehmen verdient. Der Umgang mit Legacy Software ist in den letzten Jahren vermehrt in den Fokus vieler Unternehmen geraten. Das liegt einerseits an den demographischen Faktoren: Viele erfahrene Software-Entwickler der Babyboomer-Generation gehen in den nächsten Jahren in den wohlverdienten Ruhestand und mit ihnen auch das fachliche und technische Wissen über die Legacy Software. Auf der anderen Seite stehen viele IT-Abteilungen vor der Herausforderung, bestehende Anwendungen technologisch zu modernisieren, um z.B. die Vorteile der Cloud auszunutzen oder Benutzeroberflächen anzubieten, die heutige Anforderungen an die User Experience erfüllen.
In einer dreiteiligen Artikelserie werde ich verschiedene Aspekte der Legacy Ablösung betrachten. Im ersten Teil ging es um die Strategien auf Ebene eines Unternehmens und der gesamten Anwendungslandschaft. Im zweiten Teil wurden konkrete Taktiken zur Modernisierung einzelner Anwendungen vorgestellt. Dieser dritte Teil behandelt mehrere Architekturmuster, um ein schrittweises Reengineering von Legacy-Anwendungen im laufenden Betrieb zu ermöglichen.
Die ersten beiden Teile dieser Serie finden Sie hier:
Legacy abschotten mit dem Anti-Corruption Layer
Beim schrittweisen Reengineering folgt die neue Anwendung oft den Prinzipien des Domain-Driven Design [2]. Für die Integration von Legacy-Anwendungen oder Legacy-Komponenten in das Domänenmodell der neuen Anwendung schlägt Domain-Driven Design (DDD) die Verwendung eines Anti-Corruption Layers vor. Als Nutzer von Schnittstellen eines Legacy-Systems – eines sogenannten downstream-Clients in der DDD-Terminologie – wird eine isolierende und übersetzende Schicht eingeführt, die Schnittstellen des Legacy-Systems in das eigene Domänenmodell übersetzt. Diese Übersetzung entkoppelt die Domänenmodelle und vermeidet somit eine Korruption des fachlichen Domänenmodells der neuen Anwendung mit Domänenobjekten der Legacy-Anwendung. Das bringt Vorteile für beide Anwendungen: Die Legacy-Anwendung muss nicht angepasst werden, um eine Schnittstelle gemäß der Anforderungen des Domänenmodells der neuen Anwendung zu liefern. Und die neue Anwendung kann ein Domänenmodell auf der grünen Wiese ohne Abhängigkeiten zu Altanwendungen verwenden.
Betrachten wir das konkrete Beispiel in Abb. 1 aus der Versicherungsbranche. Die neue Anwendung ist eine Vertragsverwaltung für Versicherungsverträge und arbeitet im Domänenmodell mit Entitäten wie Kund:in oder Beitragszahler:in. Obwohl beide Entitäten natürliche Personen sind, unterscheiden sich die benötigten Attribute gemäß DDD für eine Kund:in oder Beitragszahler:in stark und sollten deswegen im Modell auch als eigene Entitäten entsprechend modelliert werden. Während für eine Kund:in eine große Menge von Attributen erfasst werden müssen, um den Vertrag zu verwalten (z.B. Adressdaten), liegen für die Beitragszahler:in vielleicht nur ein Name und die Kontodaten in Form einer IBAN vor. Bestehende Legacy-Systeme zur Verwaltung von Partnern bieten oft ein generalisiertes Datenmodell zur Abbildung vieler verschiedener Partnertypen an und unterscheiden unterhalb der Entität Partner über Partnerrollen die benötigten Attribute oder auch die möglichen Verknüpfungen zu einem Versicherungsvertrag. Die Schnittstelle zum Lesen von Partnerdaten liefert dementsprechend eine Vielzahl von Attributen, bei denen je nach Rolle ein Großteil nicht gefüllt sind. Für die Verwendung im DDD-Domänenmodell der neuen Vertragsverwaltung ist diese Schnittstelle nicht direkt geeignet, da es modellierte Entitäten wie Kund:in oder Beitragszahler:in mit dem passenden Ausschnitt der Attribute gibt. An der Stelle kommt das Anti-Corruption Layer (ACL) zum Tragen, das Schnittstellen wie leseKunde oder leseBeitragszahler passend zum DDD-Domänenmodell bereitstellt. In der Implementierung der Schnittstellen wird dann auf die generische Schnittstelle lesePartner des Partnersystems übersetzt. Dadurch reduziert das ACL aus der Gesamtmenge der Partner auf die in der Vertragsverwaltung benötigten Rollen und vermeidet eine Korruption des Domänenmodells der Vertragsverwaltung mit zusätzlichen Rollen aus dem Domänenmodell des Partnersystems.
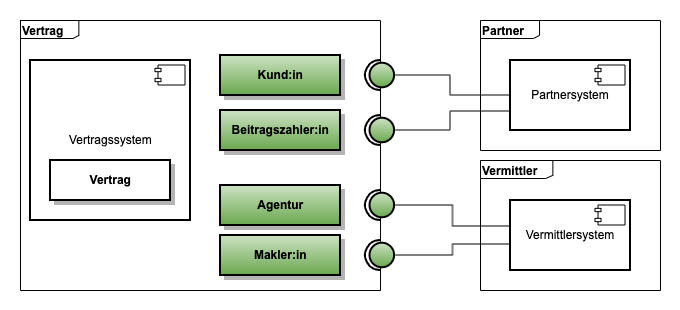
Ganz analog fungiert ein zweites ACL an der Schnittstelle zum Vermittlersystem, das verschiedene Vermittlertypen wie Versicherungsagenturen, die ausschließlich für die jeweilige Versicherung arbeiten, und Makler:innen, die für mehrere Versicherungen beraten, verwaltet. Auch hier gibt es in der neuen Anwendung eigene Entitäten Agentur und Makler:in im DDD-Domänenmodell, weil diese Unterscheidung bei den Prozessen der neuen Anwendung eine Rolle spielt und die Menge der Attribute für beide Typen sich unterscheiden. Die Implementierung des ACL fungiert auch hier als Übersetzer von der Schnittstelle des Vermittlersystems in das Domänenmodell der neuen Anwendung.
Agiles Reengineering mit dem Strangler Fig Pattern
Das Strangler Fig Pattern [3] ist ein bewährtes Architekturmuster für die schrittweise Ablösung von Legacy-Systemen und damit für ein agiles Reengineering. Die Grundidee orientiert sich an der Natur: Wie die Würgefeige einen alten Baum langsam umschließt und ihn schließlich vollständig umfasst, wird beim Strangler Fig Pattern die neue Software schrittweise um die bestehende Legacy-Anwendung herumgebaut. Im ersten Schritt fängt die neue Software zwar alle Nachrichten an das Legacy-System ab, leitet die Anfragen aber an das Legacy-System weiter. Neue Funktionalitäten werden nicht mehr im Altsystem, sondern direkt im neuen System implementiert. Bestehende Funktionalitäten werden nach und nach migriert, bis das Legacy-System vollständig abgelöst und abgeschaltet werden kann. Der große Vorteil: Das Risiko eines Big-Bang-Releases wird vermieden und der laufende Betrieb bleibt weitgehend unbeeinträchtigt.
In der Praxis bedeutet das, dass beide Systeme – das alte und das neue – für eine gewisse Zeit parallel betrieben werden. Über Routing-Mechanismen oder Schnittstellen wird sichergestellt, dass Anfragen entweder vom Legacy-System oder bereits vom neuen System beantwortet werden. Die Migration erfolgt dabei iterativ: Einzelne Module, Services oder fachliche Domänen werden isoliert und in die neue Architektur überführt. Dies ermöglicht eine bessere Kontrolle über die Migration, erleichtert das Testen und reduziert die Komplexität, da nicht das gesamte System auf einmal migriert werden muss. Herausforderungen wie die Integration in bestehende Release- und DevOps-Prozesse sowie die Synchronisation von Daten und Schnittstellen müssen dabei frühzeitig adressiert werden [4].
Das Strangler Fig Pattern in der Praxis
In der Praxis wird das Strangler Fig Pattern in mehreren Schritten angewendet. Bei der Migration einer Java EE Anwendung zu Spring Boot [5] meiner Kolleg:innen Pia Diedam und Christian Nockemann konnte die bestehende fachliche Logik gemäß Abb. 2 in vier aufeinander aufbauende Module aufgeteilt werden. Im Ausgangszustand kommunizieren die Module per Remote Method Invocation (RMI). Als Vorarbeiten erfolgten migrationsvorbereitende Maßnahmen zur fachlichen Optimierung der bestehenden API im Legacy-Code. Dann wurden im ersten Schritt die beiden Module Repo für das Repository und Core für die Kern-Geschäftslogik nach Spring Boot migriert. Die API für Core blieb dabei fachlich erhalten und wurde lediglich technisch von RMI auf eine REST-API umgestellt. Die Aufrufe der nutzenden Module Auftrag und Banking wurden dementsprechend auf HTTP-Aufrufe umgestellt.
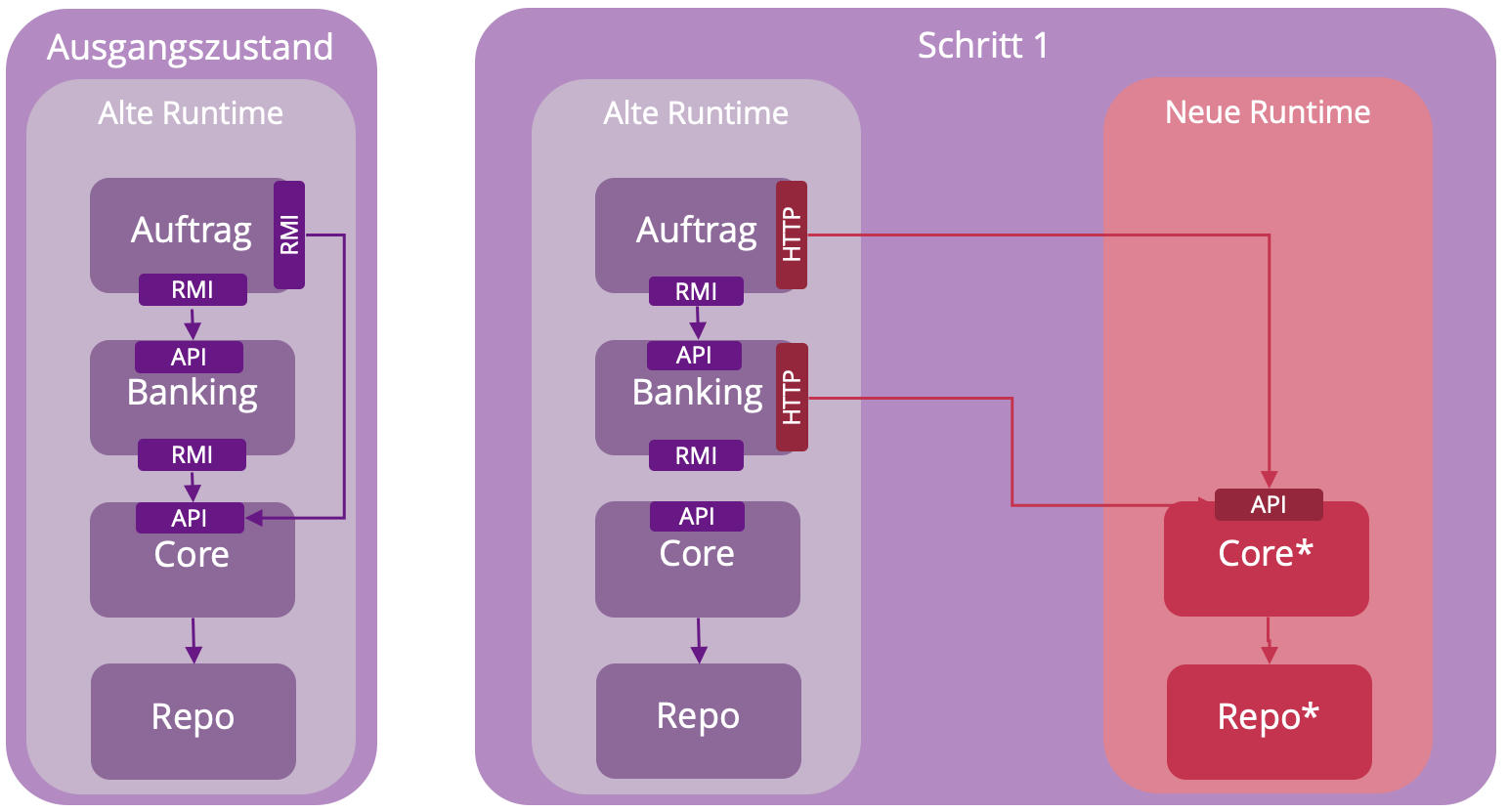
In zwei weiteren Schritten wurden die Module Banking und danach Auftrag nach Spring Boot migriert und die Aufrufe zwischen den Modulen von RMI auf HTTP umgestellt, sodass schließlich alle Module in der neuen Laufzeitumgebung zur Verfügung standen wie in Abb. 3 dargestellt. Der aufmerksamen Leser:in wird nicht entgangen sein, dass die Reihenfolge der Migration von innen (Core) nach außen (Auftrag) erfolgt und nicht wie im originären Strangler Fig Pattern von außen nach innen als graduelles Umschlingen und Erwürgen. Im vorliegenden Fall war das eine pragmatische Entscheidung basierend auf den konkreten Bedürfnissen des Migrationsprojekts, bei dem die internen Abhängigkeiten zwischen den Modulen stärker im Vordergrund standen als Schnittstellen nach außen zu Drittsystemen. Das Vorgehen von innen nach außen war im konkreten Projekt besser testbar und damit risikoärmer. Für mich ist auch das eine wichtige Lehre aus der Praxis: ein Muster sollte niemals unreflektiert nach Lehrbuch umgesetzt werden, sondern immer an die konkreten Anforderungen und Rahmenbedingungen des Projekts angepasst werden.
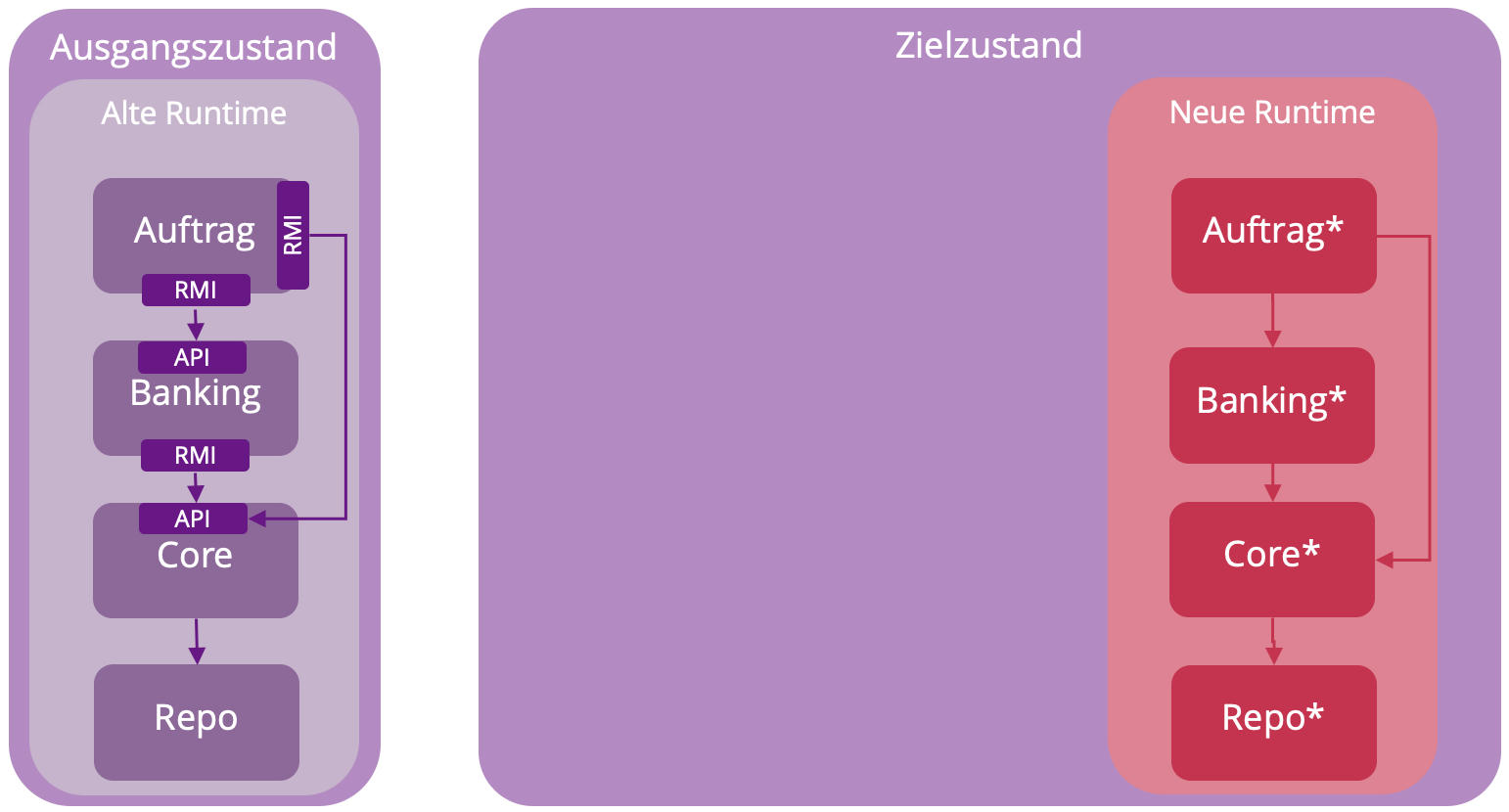
Das Strangler Fig Pattern als iteratives Vorgehensmodell muss mit der laufenden Weiterentwicklung in Einklang gebracht werden. Während der Migrationsphase müssen sowohl die Legacy-Umgebung als auch die neue Anwendung kontinuierlich deploybar sein. Durch die parallele Entwicklung in zwei Welten wird das Entwicklungsteam besonders gefordert und bei Features und anderen Arbeitspaketen sollte transparent sein, in welcher Umgebung diese jeweils umgesetzt werden müssen. Auch an den Integrationstest werden besondere Herausforderungen gestellt, da einerseits sichergestellt werden muss, dass die Neuentwicklung keine neuen Fehler gegenüber dem Legacy-System aufweist und andererseits das Zusammenspiel von Legacy-Komponenten und neu entwickelter Software gut getestet werden muss, um die fachliche Korrektheit des Gesamtsystems sicherzustellen. Auch Qualitätsanforderungen wie z.B. Performance spielen eine große Rolle und sollten idealerweise vor der Migration in Form von Qualitätsszenarien expliziert und entsprechend getestet werden.
Brücken zur Legacy mit Bridge to the New Town
Ein alternatives – ebenfalls iteratives – Muster ist The Bridge to the New Town [6]. Hier wird das Bild vom Städtebau für die gewachsene Anwendungslandschaft eines großen Unternehmens betrachtet. In der Altstadt befinden sich die Legacy-Anwendungen und in der Neustadt werden schrittweise neue Anwendungen implementiert. Der Fokus dieses Musters liegt auf der Brücke zwischen der Altstadt und der Neustadt, die beide Landschaften integriert und insbesondere Daten zwischen den Systemen über die Brücke repliziert. Das Muster ist aus der Erkenntnis motiviert, dass Anwendungen viele Schnittstellen zu anderen Systemen haben. Ein abzulösendes System in der Altstadt ist in vielfältiger Weise mit anderen Anwendungen in der Altstadt verbunden. Die Neuimplementierung in die Altstadt zu integrieren, würde Aufwände und Komplexität in die Höhe treiben, da eine Vielzahl weiterer Anwendungen in der Altstadt an das neue System angebunden werden müssten.
Aus diesem Grund bleibt der Altbau mit den anderen Legacy-Anwendungen in der Altstadt verbunden und leitet eingehenden schreibenden Datenverkehr über die Brücke in die Neustadt zur neuen Anwendung weiter. Die geschriebenen Daten werden dann über die Brücke zurück an den Altbau repliziert. Damit können lesende Datenzugriffe aus der Altstadt über bestehende Schnittstellen vom Altbau beantwortet werden. Die Abhängigkeiten bei der Migration einer Anwendung werden damit deutlich reduziert und die Migration einer Anwendung kann weitestgehend isoliert und ohne größere Anpassungsaufwände in den anderen Altbauten der Altstadt durchgeführt werden. Das Muster folgt der Taktik “migrate the data – toss the code”, die im vorherigen Artikel der Serie vorgestellt wurde.
Transaktionen mit dem Saga Pattern
Legacy-Systeme sind häufig Monolithen und nutzen intensiv technische Transaktionen (insbesondere ACID-Transaktionen einer Datenbank), um die Konsistenz der Daten über die gesamte Anwendung sicherzustellen. Bei der Modernisierung werden die Neubauten üblicherweise kleiner geschnitten und in modulithische Anwendungen oder einzelne Microservices aufgeteilt. Die Vorteile der fachlichen Kapselung gehen mit einem Verlust von technisch übergreifenden Transaktionen einher, d.h. die Konsistenz der Daten zwischen den Modulithen und Microservices kann nicht mehr über eine Transaktion in einer geteilten gemeinsamen Datenbank erfolgen.
Für fachliche Transaktionen über verteilte Microservices hinweg ist das Saga Pattern [7] in den letzten Jahren bekannt geworden, das ursprünglich kreiert wurde, um langlebige Transaktionen in Datenbanken abzubilden [8]. Im Gegensatz zu schwergewichtigen Protokollen für verteilte Transaktionen wie Two-Phase-Commit, die eine zusätzliche technische Komplexität mitbringen und die Skalierung der beteiligten Microservices beeinträchtigen, bietet das Saga Pattern ein Muster, um die fachliche Konsistenz über die verteilten technischen Transaktionen sicherzustellen. Die Grundidee ist einfach: die fachliche Transaktion besteht aus einer Menge einzelner technischer Transaktionen, z.B. bei der Buchung einer Reise aus den einzelnen Buchungen für Hotel, Flug und Mietwagen. Diese Einzeltransaktionen werden ausgeführt und falls alle drei erfolgreich sind, ist auch die fachliche Gesamt-Transaktion erfolgreich. Bei Fehlern in einer Transaktion müssen die anderen Transaktionen rückgängig gemacht - kompensiert - werden. Dazu muss jeder Microservice eine Stornofunktion für die Buchung bereitstellen, damit Hotel und Mietwagen storniert werden können, falls der Flug ausfällt.
Das Saga-Pattern ist auf Durchsatz optimiert und vermeidet Datenbank-Sperren wie im Two-Phase-Commit-Protokoll. Dabei können temporäre Inkonsistenzen im fachlichen Zustand des Gesamtsystems auftreten, die die aber unter dem Stichwort Eventual Consistency mit einer entsprechend robusten Architektur von modernen Anwendungen toleriert werden können. Die Endanwender:innen bekommen die Inkonsistenzen im Idealfall nicht mit oder sind eine gewisse Toleranz im Sekunden- oder Minutenbereich gewohnt und nicht beunruhigt, dass die Bestätigung für den Mietwagen etwas später als die Bestätigung für den Flug eintrifft. Technische Transaktionen und eine absolute Vermeidung von Inkonsistenzen werden trotzdem häufig als Argumente gegen eine Modernisierung und Verteilung der Anwendungen ins Feld geführt. Darauf antworte ich üblicherweise mit dem Beispiel einer Banküberweisung, die bis heute nicht gleichzeitig auf beiden beteiligten Konten durchgeführt wird und bei der es akzeptierte Praxis ist, dass das Geld auf meinem Konto schon abgebucht ist, bei der:m Empfänger:in aber erst in ein bis zwei Tagen eintrifft. Wenn diese Inkonsistenz für den - in einer Marktwirtschaft nicht ganz unwichtigen - Geschäftsprozess Geldtransfer akzeptabel ist, sollte das auch für die Use Cases anderer Geschäftsanwendungen möglich sein. Und Kompensationen wie eine Rücklastschrift oder Clearingstellen sind aus der Domäne Geldtransfer ebenfalls wohlbekannt. Sehr überzeugend und lesenswert ist in dem Kontext Gregor Hohpes Blog, warum Starbucks keinen Two-Phase-Commit einsetzt [9].
Transaktionen mit der Transactional Outbox
Ein zweites Muster, um technische Transaktionen bei der Transition von einem Monolithen zu verteilten Anwendungen aufzubrechen, ist Transactional Outbox [10]. Auch hier ist der Startpunkt im Praxisbeispiel Abb. 4 ein monolithisches System, das Kunden- und Kontodaten einer Bank in einer gemeinsamen Datenbank in einer technischen Transaktion speichert. Auch die Beziehung der Kunden zu den Konten wird in derselben Datenbank und innerhalb einer ACID-Transaktion angelegt.
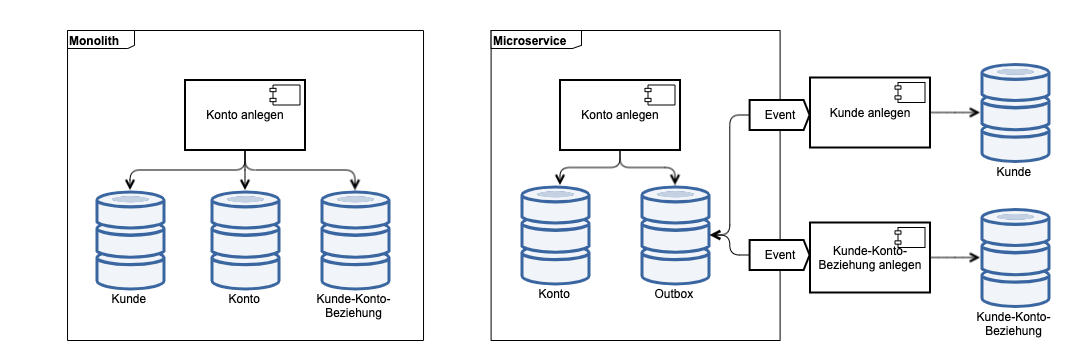
Bei einer Neuimplementierung im Rahmen einer Microservice-Architektur für die Kontenverwaltung wird diese als eigener Bounded Context in einem separaten System mit einer separaten Datenbank angelegt. Im Geschäftsprozess Konto anlegen soll aber natürlich weiterhin eine Beziehung zum Kunden als Kontoinhaber angelegt werden, der in der Kundenverwaltung gespeichert wird. Die Idee der Transactional Outbox ist, Events zur Anlage von Entitäten in anderen Anwendungen und Events für die Anlage der Beziehungen zwischen den Entitäten innerhalb einer technischen Transaktion gemeinsam mit den Entitäten innerhalb der eigenen Anwendung abzuspeichern. Im konkreten Beispiel werden Events für die Entität Kunde und die Beziehung zwischen Kunde und Konto in einer Outbox-Tabelle innerhalb des Konto-Microservice in einer Transaktion gemeinsam mit dem Konto selbst abgespeichert. So wird die fachliche Konsistenz “ein Konto muss eine Beziehung zu einem Kunden als Kontoinhaber besitzen” sichergestellt.
Die Events zur Anlage des Kunden und der Kunde-Konto-Beziehung können dann zeitlich von der Konto-Datenbank-Transaktion entkoppelt ausgeführt werden. Dabei muss sichergestellt werden, dass die Events garantiert ausgeführt werden, damit keine dauerhaften fachlichen Inkonsistenzen entstehen. Aber eine technische Kopplung zwischen den beiden Systemen oder Microservices wird vermieden. Als Rahmenbedingung müssen die Services für die Anlage von Kunde und der Kunde-Konto-Beziehung idempotent sein, d.h. die Services müssen mehrfach wiederholt aufgerufen werden können, ohne die entsprechenden Entitäten mehrfach anzulegen.
Replikation für Performance
Die Performance der Anwendung ist neben der Transaktionalität die zweite große Herausforderung bei Modernisierungsvorhaben. Gerade beim Wechsel von Monolithen, insb. auf dem IBM-Mainframe, hin zu verteilten Systemen on-premise oder in der Cloud entstehen inhärente Performanceprobleme durch die Zielarchitektur. Das liegt an den Eigenschaften verteilter Systeme [11], wie z.B. der Netzwerklatenz zwischen Application Server und Datenbanksystem, die es auf dem monolithischen Mainframe als Quellsystem nicht gibt. Dadurch sind Massendatenverarbeitung wie Batchanwendungen rein prinzipiell aufgrund der Hardwarearchitektur nicht so performant nach einer Modernisierung mit Java Batch wie vorher in COBOL. Auf der anderen Seite bieten verteilte Systeme natürlich auch eine Reihe von Vorteilen, sodass eine bessere Skalierung durch eine parallele Ausführung auf vielen verteilten Servern möglich ist und Engpässe bei der Laufzeit im nächtlichen Batchzeitfenster vermieden werden können.
Gelegentlich ist es aber sinnvoll, die Daten der modernisierten Anwendung für den effizienten Zugriff aus den Legacy-Systemen in die ursprünglichen Datenbestände zurück zu replizieren. Ganz im Sinne des Musters The Bridge to the New Town können damit nicht nur die Schnittstellen anderer Systeme der Altstadt zum modernisierten System stabil bleiben, sondern die Performance der Altstadtsysteme bleibt auch erhalten, da kein Zugriff auf die verteilten Systeme erfolgt.
Eine Replikation von Daten kann man sich auch zunutze machen, wenn die Altstadt-Systeme nur schwer an moderne Technologien wie z.B. Kafka anschlussfähig sind. Beim Aufbau einer eventbasierten Architektur mit Kafka ist die Einlieferung der Events aus Legacy-Systemen schwierig bis unmöglich, weil die Legacy-Technologien keine Unterstützung für Kafka anbieten. In dem Fall kann eine Replikation der Daten aus der Legacy-Datenbank über ein Change-Data-Capture-Verfahren z.B. mit Debezium in Kafka-Topics eine gute Brückentechnologie sein, um den Anschluss an Kafka ohne eine Anpassung der Altsysteme herzustellen.
Fazit: Alle Muster sind falsch aber manche sind nützlich
Angelehnt an das bekannte Zitat “Alle Modelle sind falsch, aber manche sind nützlich” von George Box, lässt sich dasselbe auch für die vorgestellten Muster konstatieren. Die Muster sollten nicht wie Werkzeuge bei jeder Legacy-Migration unreflektiert eingesetzt werden, sondern sind als Anregungen zu verstehen, um analoge Probleme zu erkennen und mögliche Lösungsansätze zu entwickeln. Wie im Praxisbeispiel für das Strangler Fig Pattern sollten Muster nur als Inspiration für das konkrete Vorgehen dienen, das sich an den Anforderungen und Rahmenbedingungen des Projekts orientiert.
Genauso wenig gibt es grundsätzlich bessere oder schlechtere Muster, sondern manche sind besonders geeignet für einen gewissen Einsatzzweck und manche weniger. Die vorgestellte Menge an Mustern ist sicherlich nicht vollständig und es gibt weitere Sammlungen in [1] und [12]. Der Umgang mit Legacy-Software wird zukünftig sicherlich nicht weniger wichtig sein als die Neu-Implementierung auf der grünen Wiese. Unsere Architektur-Methodik hängt aber noch etwas hinterher und befasst sich zu großen Teilen mit der Neu-Implementierung. Diese dreiteilige Artikelserie zur Legacy-Ablösung war als kleines Gegengewicht zum Fokus auf die immer neuesten Technologien und Architekturtrends gedacht.
Dieser Blogpost wurde zuerst als Artikel im Java Magazin 10/2025 veröffentlicht: Muster der Legacy- Ablösung
Links und Literatur
[1] Serge Demeyer, Stéphane Ducasse, Oscar Nierstrasz: Object-Oriented Reengineering Patterns
[2] Eric Evans: Domain-Driven Design - Tackling Complexity in the Heart of Software, Pearson International, 2003.
[3] Martin Fowler: Strangler Fig
[4] Pia Diedam: Strangler Pattern - Herausforderungen bei der Umstellung auf Spring Boot
[5] Christian Nockemann: Weg von Java EE - so gelingt die Migration
[6] Wolfgang Keller: The Bridge to the New Town - A Legacy System Migration Pattern
[7] Bernd Rücker: Saga: How to implement complex business transactions without two phase commit
[8] Hector Garcia-Molina, Kenneth Salem: Sagas, ACM SIGMOD Record, Volume 16, Issue 3, 1987
[9] Gregor Hohpe: Starbucks Does Not Use Two-Phase Commit
[10] Chris Richardson: Pattern: Transactional outbox
[11] Peter Deutsch: Fallacies of Distributed Computing
[12] Ian Cartwright, Rob Horn, and James Lewis: Patterns of Legacy Displacement

