bpmn.ai - Geschäftsprozesse mit Hilfe von KI optimieren
Die Themen BPMN und KI sind derzeit in aller Munde. Da liegt die Frage nahe, welche Potenziale sich durch die Verbindung der beiden Themen ergeben können.
Es geht dabei zum einen darum, mit dem Einsatz von Methoden der künstlichen Intelligenz nützliche Informationen aus Daten zu gewinnen, die durch die Ausführung von Geschäftsprozessen entstehen ("Process Science"). Zum anderen wird betrachtet, wie KI-Systeme zur Modellierung, Optimierung und weiteren Automatisierung der Geschäftsprozesse genutzt werden können.
Die bpmn.ai-Ideen umfassen dabei den gesamten Zyklus von der Extraktion der relevanten Daten, über die Anwendung von KI-Methoden darauf (wie z. B. Agenten oder spezifische Machine-Learning-Modelle), bis hin zur Integration und Orchestrierung von KI-unterstützten Aktivitäten im Geschäftsprozess durch Agenten.
Schön daran: Unsere Muster und Methoden sind technologieunabhängig - typisch für viadee. Sie sind leicht mit Prozessorchestrierungs-Werkzeugen wie Camunda zu realisieren, aber auch mit n8n oder Call-Center-Software.
Ihr Ansprechpartner für BPMN.AI

bpmn.ai – KI-Prozessmuster im Zusammenspiel
Ein Beispiel: Ein Schadensprozess einer Versicherung soll entscheiden, ob eine externe Prüfung notwendig ist. Grundlage ist eine manuelle Entscheidung, zu der die im Verlauf des Prozesses Daten gesammelt wurden. Als letzter Schritt wird, je nach Prüfungsentscheidung, die Zahlung automatisiert freigegeben oder abgelehnt. Diese Konstellation ist in Unternehmensprozessen sehr häufig zu finden. Ein Python-Script, dass die Entscheidung trifft, ist oft schnell geschrieben. Für eine Produktivsetzung bietet sich eine verantwortungsvolle Kombination von bpmn.ai Patterns an.
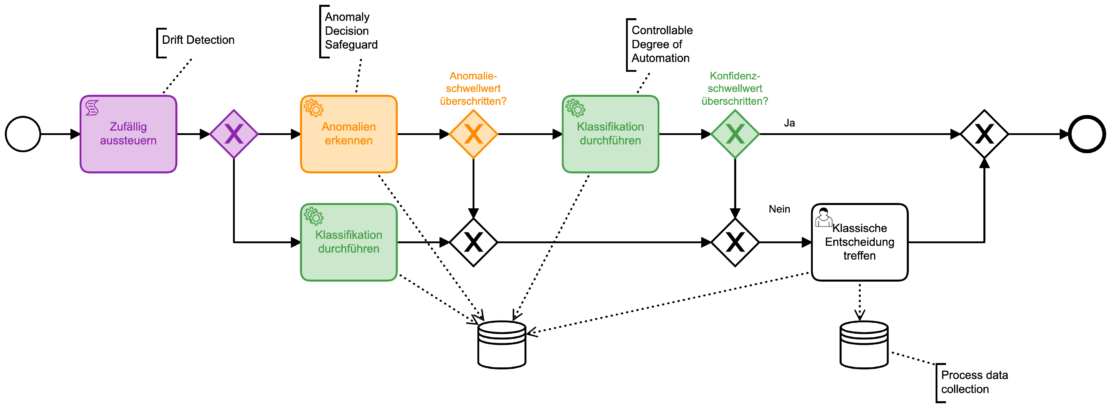
Zunächst wird zufällig ein Teil der eingehenden Fälle ausgesteuert. Damit sicher wir uns für die Zukunft ab, indem wir die ausgeschleusten Fälle von KI-Logik und Mensch entscheiden lassen und die Ergebnisse vergleichen (Drift Detection). Im nächsten Schritt bietet sich eine Anomalieerkennung als Sicherheitsmaßnahme an. Es wird Sonderfälle geben, die sich nicht für automatische Verarbeitung eignen. Sie automatisch zu bemerken ist aber oft relativ einfach. Erst hinter diesem „Filter“ kommt es zu einer Entscheidung des KI-Modells, die möglicherweise den Prozess-Ausgang beeinflusst. Dies geschieht aber nur, wenn das Modell den Einzelfall sicher genug entscheiden kann, der gewünschte Automatisierungsgrad wird so steuerbar.
KI Agenten und BPM
Künstliche Intelligenz wird oft mit vollständiger Automatisierung oder autonomen Systemen gleichgesetzt. Doch im Kontext heutiger Geschäftsprozesse bedeutet der Einsatz von KI vor allem: gezielte Unterstützung an konkreten Stellen mit klarer Einbettung in bestehende Abläufe und nachvollziehbarer Kontrolle.
Mit deterministischen Prozessmodellen, die den Input, die Pfade und den Output vorgeben sowie den autonomen KI-Agenten, die selbst Entscheidungen treffen öffnet sich ein interessantes und hoch relevantes Gebiet aus beiden Welten: der Einsatz von KI-Agenten in BPM.
Was sind KI-Agenten?
KI-Agenten sind spezialisierte Softwarekomponenten, die in der Lage sind, bestimmte Aufgaben im Prozesskontext selbstständig zu übernehmen. Dazu gehören etwa:
die Analyse und Klassifikation von Dokumenten (vielleicht mit einer Recherche in anderen Dokumenten)
die schnelle Verarbeitung von unstrukturierten Daten (vielleicht im Abgleich mit einem Bestandssystem)
die Priorisierung von Fällen oder die Ableitung von Empfehlungen (mit Plänen und Begründungen)
das Routing von Informationen zu den richtigen Stellen oder Rollen (wenn der Automatismus nicht weiter weiß)
Und was nicht?
Es geht nicht darum Prozesse pauschal oder vollständig zu ersetzen oder ohne menschliches Eingreifen autonom zu handeln. Moderne KI-Agenten sind bewusst so konzipiert, dass sie mit ihren Vorteilen der Autonomie in bestehende deterministische Prozessmodelle eingebettet werden, mit klar definierten Eingabedaten, Entscheidungsspielräumen und Übergabepunkten an menschliche Akteure.
Nicht autonom: Entscheidungen werden nur im definierten Rahmen getroffen.
Nicht intransparent: Ergebnisse sind nachvollziehbar dokumentiert (Stichwort: Explainable AI).
Nicht unkontrolliert: Menschliche Kontrolle und Eingriffsmöglichkeiten bleiben jederzeit erhalten.
KI-Agenten sind ein evolutionärer Schritt in Richtung intelligenter Prozessunterstützung. Sie ermöglichen es, bestehende Abläufe effizienter, datengetriebener und robuster zu gestalten – ohne an Steuerbarkeit oder Vertrauen zu verlieren.
So gelingt die KI Integration im Geschäftsprozess-Management kontrolliert
KI-Agenten entfalten ihren Mehrwert dann, wenn sie sauber in bestehende Prozesslandschaften integriert sind. Dabei geht es nicht nur um Technik, sondern auch um Governance und Nachvollziehbarkeit. Der typische Weg zur Integration umfasst folgende Schritte:
Identifikation geeigneter Prozesspunkte
Wo sind im Prozess wiederkehrende Entscheidungen, Bewertungen oder Klassifikationen nötig? Hier lohnt der gezielte KI-Einsatz.
Definition von Inputs und Outputs
Klar definieren, welche Daten der Agent benötigt und welche Entscheidung oder Empfehlung er liefern soll.
Einbindung als Service oder Komponente
Technisch wird der KI-Agent meist als gekapselter Microservice oder API-basiert eingebunden – lose gekoppelt und austauschbar.
Human-in-the-Loop festlegen
An welchen Stellen soll der Mensch eingreifen können? Eskalationspfade, Confidence Thresholds und Overrides sorgen für Vertrauen.
Monitoring & Nachvollziehbarkeit (Explainable AI)
Entscheidungen von KI-Agenten müssen im Kontext dokumentierbar und erklärbar sein – für Nutzer:innen, Auditoren und Systeme.
Testbarkeit eines nicht-deterministischen Subsystems
Da KI-Agenten autonom und nicht-deterministisch Handeln muss sichergestellt werden, dass sie hinreichend getestet werden. Das inkludiert unterschiedliche Inputs und resultierende Pfade sowie Outputs die statistisch zu prüfen sind.
Das Ergebnis ist kein autonomer Black-Box-Prozess, sondern eine intelligente Prozessarchitektur, in der Mensch und Maschine gemeinsam agieren, um die Prozesse flexibel, sicher und zukunftsfähig zu gestalten.
Auf der NAVIGATE 2026 hat bspw. Uwe Könnel (Head of Digitalization & AI Technologies FRABA GmbH) einen Geschäftsprozess vorgestellt, der in Bezug auf diese „Checkliste“ Vorbildcharakter hat.
Dieser Inhalt kann nur angezeigt werden, wenn du der Verwendung von Funktionellen-Cookies zustimmst. Bitte akzeptiere diese Cookies, um das Laden zu ermöglichen.
Process Engines sind eine Chance für den Einsatz von KI
Die gesammelten Daten von vergangenen Prozessläufen enthalten sowohl die Informationen, welche der manuellen Entscheidung zur Notwendigkeit einer externen Prüfung zugrunde lagen, als auch die Entscheidung selber, da diese jeweils als Prozessvariablen vorliegen und gespeichert werden. Durch die Aufbereitung dieser Daten und das Anlernen eines ML-Modells kann ein Entscheidungsmodell für eine KI-gestützte Prozessoptimierung erstellt werden. Eine manuelle Entscheidungsaktivität kann so durch eine automatisierte Aktivität unterstützt werden.
Dabei ist wichtig zu verstehen, dass ML-Modelle nicht das Ende der DMN-Tabellen darstellt. Das Gegenteil ist der Fall. Jede (fachliche) DMN-Tabelle ist ein potenzieller Business Case für Data Science-Verfahren und sowohl ein „gemachtes Nest“ (viele Daten sind schon im Prozess greifbar) als auch ein mögliches Betriebsmodell („Serviceless AI„).
Integration und Orchestrierung von KI-Services
KI-Services stehen selten allein da. BPMN-Prozesse, die bspw. mit der Camunda-Plattform ablaufen, bieten sich an, um ihren Einsatz zu orchestrieren. Auf einer gröberen Eben kann die Integration der Künstlichen Intelligenz in den Prozess in verschiedenen Stufen oder auch Reifegraden gestaltet werden:
- ML-Model wird manuell generiert.
- Ergebnisse werden zur Optimierung des Prozesses verwendet.
- Keine Integration von KI im Prozess. Erlernte Regeln können aber ggf. als DMN integriert werden.
- ML-Model wird automatisch generiert.
- KI wird parallel zur manuellen Aktivität im Prozess integriert und dessen Entscheidungen protokolliert.
- Entscheidungen im Prozess basieren weiterhin auf manueller Aktivität.
- ML-Model wird automatisch generiert.
- KI wird manueller Aktivität vorangestellt.
- Bei geringer Konfidenz der KI wird die Entscheidung manuell getroffen.
- KI-Anteil kann gewählt werden, je nachdem wie sicher die KI sich mindestens sein soll.
- ML-Model wird automatisch generiert.
- Kontrollierte Ausführungsumgebung mit Freigabeprozessen etc.
- Entscheidung, ob in einem Fall die Entscheidung durch die KI oder manuell getroffen wird, wird so getroffen, dass eine hohe Automatisierung erfolgen kann, jedoch weiterhin ein sinnvolles Lernen der KI durch neue manuelle Entscheidungen abgesichert ist.
Unsere Erfahrungen mit KI im Prozess-Praxiseinsatz - Schon lange vor dem Hype
Für Duni wird eine Prognose der Laufzeit des überarbeiteten Profile-Print-Prozesses daraus abgeleitet, indem beispielsweise individualisierte Servietten für Restaurants gestaltet und hergestellt werden – mit dieser Arbeit waren wir auf der CamundaCon 2018 dabei. Die Idee hat sich als gut übertragbar erwiesen. Zusammen mit der Westfälischen Provinzial Versicherung AG verfolgen wir mit gleicher Technik die Idee, um die Notwendigkeit von Rechnungsprüfungen bei der Abwicklung von KFZ-Glasbruchfällen vorherzusagen. Das Ergebnis konnten wir auf den Versicherungsforen in Leipzig 2018 vorstellen.
Eine andere Perspektive auf bpmn.ai ist das Process Mining. Hierzu gab es einen schönen Erfolg, der in einer gemeinsamen Publikation mit der TIMOCOM Frachtenbörse sowie dem ERCIS auf der BPM 2020 im Industry-Forum geführt hat. Dort haben wir Nutzungsmuster aus einem Event-Stream einer Web-Anwendung herausgelesen und diese klassifiziert.
Ebenfalls ein schöner Erfolg war die Analyse von Process-Varianten der Warehouse-Logistik eines Industrie-Unternehmens inkl. Anomalie-Erkennung, um die Aufmerksamkeit des Prozessmanagements gezielt lenken zu können.
Gestützte Prozess-Evolution - "Prozesse werden aber nie so gelebt, wie sie modelliert sind!"
Das ist eine Erfahrung, die viele machen. Prozesse sind lebendig und zudem werden sie immer wieder mit Änderungen in der Umwelt konfrontiert, auf die sie nicht vorbereitet sind. Menschen im greifen dann zu Workarounds und improvisieren - oft an IT-Systemen vorbei, sodass dieser "Drift" auch nicht per Process Mining zu identifizieren ist. Das ist Fluch und Segen zugleich:
Ohne diese Flexibilität wären viele Prozesse gar nicht erfolgreich zu betreiben oder unnötig komplex.
Mit dieser Flexibilität verliert das Unternehmen etwas an zentraler Steuerbarkeit. Es gilt diese Workarounds strukturiert zu bemerken und zu handhaben. Manche sind Probleme, manche sind Lösungen für Probleme, von denen der Sollprozess noch nichts weiß!
Mit der Entwicklung von KI-gestützten Methoden zu diesem Zweck beschäftigt sich das viadee-Team seit 2023 im Rahmen des vom BMFTR geförderten Projekts Change.WorkAROUND zusammen mit der Universität Paderborn.
Dort sind drei Lösungsbeiträge mit KI-Bezug entstanden, um Prozess-Workarounds leichter handhabbar zu machen.
Der Workaround-Brainstormer ist ein guter Startpunkt für eine Analyse. Die Idee: Wir leiten mittels LLMs und einer Datenbank aus bekannten Workaround-Mustern Hypothesen dazu ab, welche Workarounds es in Ihrem Prozess vermutlich geben wird. Das Tool steht als Open Source zur freuen Verfügung und speichert keinerlei Daten - wir freuen uns über Feedback.
Der Workaround Curator ist ein zweites Werkzeug, dass die bekannten Herausforderungen und Lösungsansätze im Prozess verwaltet. Dahinter steckt eine Art KVP-Prozess mit einem Agentensystem: Es hilft Ideengebern ihre Workarounds strukturiert dazustellen - wenn notwendig auch anonym. Außerdem hilft das System bei Fragen vom Typ: "Hatten wir diesen Sonderfall nicht schon einmal?"
Wenn es dann zu einer Prozessveränderung kommt, dauert es oft lange, bis sie sich verbreitet hat. Oft gibt es auch nicht nur einen BPMN-Prozess zu aktualisieren, sonderen mehrere aus mehreren Perspektiven und eine Prozessdokumentation im Confluence und eine Schulungsunterlage als Powerpoint gleich noch dazu. Hier setzt unsere Idee eines Process Coherence-Checking an: Wir vergleichen die Sichten mittels KI, bewerten Wiedersprüche und weisen darauf hin. Das erhöht nicht nur die Geschwindigkeit, mit der sich Prozesse wandeln können, sondern erhöht auch die Prozess-Sicherheit.
Quelle: Schulte, M., Franzoi, S., Köhne, F., vom Brocke, J., “LLM-Enabled Business Process Coherence Checking Based on Multi-Level Process Documentation” (2025). Journal of Process Science 2 (22).
viadee mit bpmn.ai-Themen auf der Bühne



